Google和蹒跚学步的孩子有什么共同点? 两者都需要学习良好的听力技巧。

在第六届国际学习表示**议上,Google AI的研究人员Jannis Bulian和Neil Houl**y提出了一篇论文,阐明了他们正在测试以改善搜索结果的新方法。
尽管发表论文当然并不意味着正在使用或什至将要使用这些方法,但是当结果获得高度成功时,这可能会增加几率。 而且,当这些方法也与Google正在采取的其他措施结合在一起时,几乎可以肯定。
我相信这正在发生,并且这些变化对于搜索引擎优化专家(SEO)和内容创建者而言意义重大。
发生什么了?
让我们从基础开始,并着眼于正在讨论的内容。
一张图片据说价值一千个单词,所以让我们从论文的主要图片开始。
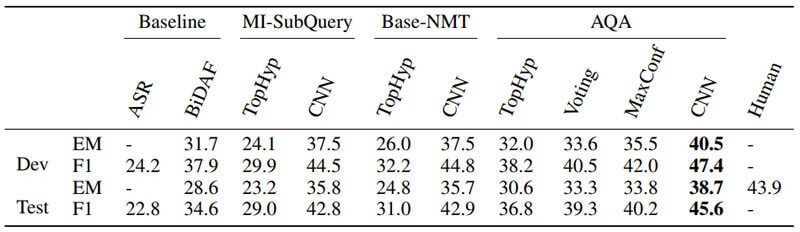
此图像绝对不值一千字。 实际上,如果没有这些文字,您可能会迷路。 您可能正在可视化搜索系统,使其看起来更像:
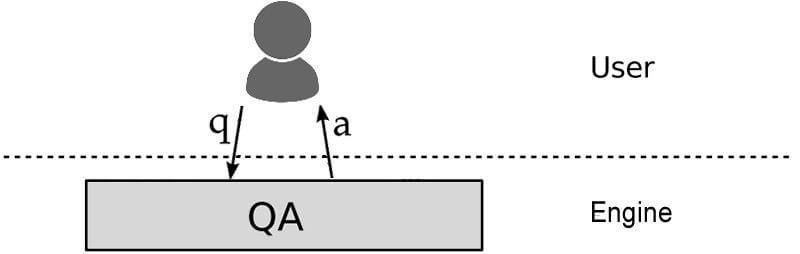
在最基本的形式中,搜索系统是:
- 用户问一个问题。
- 搜索算法解释问题。
- 将该算法应用于索引数据,并提供答案。
我们在第一张图片中看到的情况非常不同,该图片说明了本文中讨论的方法。
在中间阶段,我们看到两个部分:重新格式化和聚合。 基本上,此新过程中发生的是:
- 用户向活动的问题解答(AQA)代理的“重组”部分提出问题。
- “重组”阶段将解决这个问题,并使用下面讨论的各种方法来创建一系列新问题。
- 这些问题中的每一个都发送给“环境”(我们可以像今天您所认为的那样松散地将其视为核心算法)作为答案。
- 在“汇总”阶段,将每个生成的查询的****回AQA。
- 选择获胜答案并将其提供给用户。
看起来很简单,对不对? 唯一真正的区别是生成多个问题:站群,然后系统确定哪个是最佳问题,然后将其提供给用户。
哎呀,有人可能会争辩说,算法已经评估了许多站点,并共同努力找出最适合查询的算法。 稍作改动,但没有任何革命性的权利,对吗?
错误。 本文和方法不仅限于这张图片,还有很多其他内容。 因此,让我们继续前进。 现在该添加一些…

机器学习
这种方法真正强大的地方在于机器学习的应用。 这是我们需要对初始故障进行询问的问题:
系统如何从提出的各种问题中进行选择?
哪个问题给出了最佳答案?
这是非常有趣的地方,结果令人着迷。
在测试中,Bulian和Houl**y首先提出了一系列类似“ Jeopardy!”的问题(如果您观看演出,就会知道答案确实如此)。
他们这样做是为了模仿需要人的思维来推断对与错的情况。
如果您不熟悉游戏节目“ Jeopardy!”,请使用以下快速剪辑帮助您理解“问题/答案”的概念:
面对复杂的信息需求,人类可以通过重新构造问题,进行多次搜索以及汇总响应来克服不确定性。 受人类提出正确问题的能力的启发,我们提供了一种代理商,可以为用户学习执行此过程。
这是“ Jeopardy!”之一算法提出的问题/答案。 我们可以看到如何将问题转换为查询字符串:
对于这位巫师和曾经的外科医生来说,旅行似乎不是问题。 星体投射和传送不会有问题。
回答这个问题并非易事,因为它需要收集各种数据,还需要解释常见的隐秘问题本身的格式和上下文。 实际上,如果没有人发布类似“ Jeopardy!”之类的问题,我认为Google当前的算法将无法返回正确的结果,而这正是他们要解决的问题。
Bulian和Houl**y使用“ Jeopardy!”之类的问题对算法进行编程,并计算出成功答案,即给出正确或错误答案的答案。 该算法是从来没有意识到的,为什么一个答案是正确的还是错误的,所以它没有给出任何其它信息的过程。
由于缺乏反馈,算法无法获得成功指标,只有获得正确答案时,它什么也做不到。 这就像在类似于现实世界的黑匣子中学习一样。
他们从哪里得到问题的?
测试中使用的问题来自哪里? 在重新制定阶段将他们喂给“用户”。 添加问题后,该过程将:
- 从查询中删除停用词。
- 将查询小写。
- 添加了wh短语(谁,什么,什么地方,什么时候,为什么)。
- 增加了释义的可能性。
对于释义,系统使用联合国平行语料库,该语料库基本上是一个超过1100万个短语的数据集,完全与六种语言对齐。 他们产生了各种英语到英语的翻译器,它们可以调整查询但保持上下文。
结果
所以这就是所有降落我们的地方:
在对系统进行了训练之后,结果非常出色。 他们开发和训练的系统击败了所有变种,并显着提高了性能。 实际上,唯一做得更好的系统是人。
以下是最终生成的查询类型的一小部分示例:
他们开发的系统可以准确理解复杂而复杂的问题,并通过培训可以产生令人惊讶的准确度的正确答案。
那怎么了,戴夫? 这对我有什么帮助?
您可能会问为什么这很重要。 毕竟,搜索领域会不断发展,不断改进。 为什么会有什么不同?
最大的不同是搜索结果的含义。 Google最近还为ICLR会议发表了一篇论文,建议Google可以根据其他内容生产者提供的数据来生产自己的内容。
我们都知道,仅仅因为写了一篇论文,并不意味着搜索引擎实际上正在实现这一概念,但是让我们在以下情况下暂停一下:
- Google具有提供自己的内容的能力,并且该内容编写得很好。
- Google对确定正确答案的能力充满信心。 实际上,通过调整其功能,它可能会超越人类。
- Google有多个示例,它们致力于使用户留在其网站上,并点击其搜索结果,以更改布局和内容。
所有这些都叠加在一起后,我们需要问:
- 这会影响搜索结果吗? (可能会)。
- 是否会妨碍网站站长的内容制作工作?
- 它将限制我们的内容在更大范围的公众中看到吗?
同样,仅仅因为发表了论文,并不意味着内容将会得到实现。 但谷歌正在获得的在超过人体的方式与语言理解复杂的细微差别的能力。 Google也有兴趣让用户使用Google产品,因为归根结底,他们首先是一家出版公司。
你能做什么?
您做的事情与往常一样。 营销您的网站。
无论您是要优化成为自然搜索结果的前10名,还是要优化语音搜索或虚拟现实,都将出售相同数量的蓝色小部件。 您只需要进行调整,因为搜索引擎结果页面(SERP)会快速变化。
我们在这里看到的方法提出了一个重要主题,每个对搜索引擎优化(SEO)感兴趣的人都应该密切关注,这就是实体的使用。
如果查看上面由Bulian和Houl**y创建的系统生成的查询集,您会注意到,通常,它们越接近准确地理解实体之间的关系,答案就越好。
实际上,具体措辞无关紧要。 完全部署后,系统将不需要使用您或我理解的单词。 值得庆幸的是,它们使我们看到通过对实体及其关系进行分组而获得成功的方式可以使基于这些关系的答案更加可靠。
如果您只是想了解实体,那么这里有一块介绍了概念和细节。 我保证您会很快了解它们之间的关系,在我们进入下一代搜索时,您需要专注于这一领域。
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/10032.html