小型企业所有者征服SEO的指南:术语表
 如果您是一家小型企业主,并且掌握了如何根据潜在客户使用的搜索词来提高您的网站排名,那就太好了! 但是,如果不是,请不要绝望。 许多小企业主有很好的理由在搜索引擎优化(SEO)的一个或多个方面中挣扎。
如果您是一家小型企业主,并且掌握了如何根据潜在客户使用的搜索词来提高您的网站排名,那就太好了! 但是,如果不是,请不要绝望。 许多小企业主有很好的理由在搜索引擎优化(SEO)的一个或多个方面中挣扎。
虽然SEO既不是魔术也不是火箭科学,但它仍然相当复杂,而且每天都在增加。 白话可能会使每个从事SEO的人感到困惑。 规范,hreflang,架构,缓存,robots.txt,.htaccess-这些只是在构建,管理和营销网站时会遇到的众多术语中的少数。
在这个由三部分组成的系列文章的第一部分中,我们将列出并定义在为小型企业练习SEO时可能会遇到的一些最常见的术语。
一种
折页之上–这是网站访问者向下滚动之前可见的内容。 显然,它会有所不同,具体取决于访问者使用的设备。
算法–通常也称为“算法”,这是执行一组功能的数学过程或公式。 例如,一种算法确定搜索引擎索引中的哪个页面与给定搜索查询最匹配。
Alt属性–这是替代文本,编码为页面的超文本标记语言(HTML)或可扩展超文本标记语言(XHTML),如果无法在浏览器中呈现图像或其他元素,则应显示这些替代文本。
分析–通过对数据或统计数据进行系统分析得出的信息,例如网站访问者的数量,他们的登陆地域,他们的起源地以及他们何时何地退出。
锚文本–您看到的链接的可单击部分,通常是关键字短语,但可以是统一的资源定位符(URL)。 作者Doc Sheldon和www.searchengineland.com都是锚文本。
乙
B2B –企业对企业,当企业的客户是其他企业时。
B2C –企业对消费者,企业的客户是最终用户。
反向链接–从另一个网页到网页的传入链接。
Blackhat –通常以“ SEO”一词开头,blackhat最常指的是专门用来欺骗搜索引擎以使网站具有比实际价值更大的价值的做法,几乎总是违反搜索引擎的网站站长指南。
跳出率–指离开网页而不进行互动的访问者的百分比。
Bot –一种软件,可以根据预编程的输入自主执行特定任务。 这可能包括爬虫,聊天机器人或恶意机器人。
面包屑–这是页面在网站层次结构中所处位置的文本“地图”。 面包屑通常是可单击的链接,可以帮助用户回溯其步骤。 例如:
主页>关于我们>我们的团队。
浏览器–指图形用户界面,它显示HTML文件并用于浏览Internet。
C
缓存–这是Web内容在内存中的存储,以便能够更轻松地将其提供给用户。 缓存通常同时发生在服务器和浏览器上。
号召性用语(CTA) –营销信息的一部分,试图促使用户执行特定的操作。
规范–这是一个HTML元素,指示内容的原始版本或首选版本,以避免重复的内容问题。
点击率–代表点击率,即显示广告,搜索结果或单击广告的超链接的用户百分比。
转化-潜在客户或潜在客户的转化是指成功诱使用户完成所需的操作,例如购买,下载或订阅。
关联-这是指两个或多个条件之间的表观关系,其中关系可以相互依赖或可以不相互依赖。 例如,“当我走到外面时,我意识到自己很饿。” 饥饿并没有因为走到外面而引起。
爬网–网络机器人(也称为爬网程序或蜘蛛网)会按照从一个页面到另一页面的链接来系统地爬网Internet,从而确定建立万维网的连通性。 如果页面没有任何入站链接,则爬网程序几乎肯定不会找到该页面。
CSS –指级联样式表,该文件是一个文件,专用于在字体样式,大小和颜色方面告诉浏览器应如何显示页面。 它还表示其他HTML元素的大小,间距和位置。 这比插入每个单独元素时可能是高度重复的数据要有效得多。
d
深层链接–指到网站首页以外的页面的入站链接。
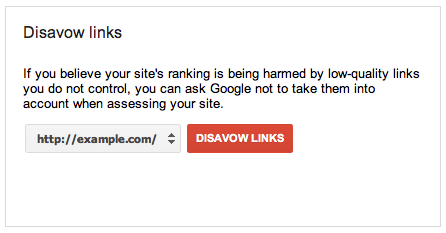
拒绝–有时,站点可能会收到来自另一个质量低下或可疑字符网页的入站链接。 如果网站所有者不希望这些链接并且无法删除它们,则网站所有者可以通过拒绝请求提交拒绝文件,其中列出了劣质链接。 基本上是说:“我们希望忽略此链接/域。”
域–每个网站都有其自己的域,该域是其URL的一部分。 在此页面的URL中,域为searchengineland 。
重复内容–指页面上与同一或另一个域上的另一页面上的内容相同或高度相似的内容块。
Ë
实体–实体是独立存在的独特事物,例如人,地方或事物,因此公司也可以是实体,一个国家或星球也可以。
外部链接–这是从一个页面到另一个域上另一个页面的出站链接。
F
框架–两个或多个文档被独立加载并显示在同一屏幕上,每个框架内。 建议不要使用框架,因为搜索引擎蜘蛛在导航框架时会遇到麻烦。
H
头-一个文档的头部包含元素,如文档的标题,元数据,脚本,款式多。 它不会包含要显示的任何页面内容。
标题–在HTML中,标题(H1至H6)可用于指示层次结构中紧随其后的内容的上下文。 它们通常用于强调页面上的标题或文本,其中H1标签具有最大的文本。
例如:
hreflang –这是HTML属性,它向搜索引擎指示页面内容所针对的语言和地理区域。
.htaccess –这是一个Web服务器配置文件,其中包含用于在某些情况下指导服务器行为的命令。 Apache服务器和其他一些国家超级计算机应用中心(NCSA)兼容服务器都使用.htaccess。
HTML –超文本标记语言。 该语言是Web的心脏,它定义了要显示的内容以及应如何显示。
HTTP –超文本传输协议。 这是万维网上使用的协议,用于定义消息的格式和传输方式以及服务器和浏览器应如何响应各种命令。
超链接–这是网络上一个点与另一点之间的超文本链接。 单击超链接会将用户带到目的地。
一世
索引–搜索引擎已爬网和建立索引的页面存储库,可将其包含在SERP中。
信息检索–系统的过程,通过该过程可以从搜索引擎的索引中搜索和提取信息。
内部链接–这些是同一域的两个网页之间的超文本链接。
IP地址– Internet协议地址。 由小数点分隔的唯一数字字符串,用于标识设备并用作互联网上的设备地址。
Ĵ
JS – JavaScript。 Web开发中使用的基于文本的编程语言,用于增强Web页面并使其更具交互性。
ķ
关键字–这些单词出现在您网页的内容中,并用于搜索查询中。 随着搜索引擎的发展,将查询与文档中找到的术语进行匹配已从完全匹配的术语演变为同义词,再到上下文相关的术语。
KPI –关键绩效指标。 这是一个可衡量的值,表明业务运营的有效性。 它可能包括诸如毛利率,现金流量,市场份额,库存周转率等因素。
大号
Linkbait –为吸引入站链接而创建的一部分内容。
链接配置文件–网站所有入站链接的汇总显示为搜索引擎提供了其他网站所感知的网站价值的图像。
日志文件–记录Web服务器活动的文件。
中号
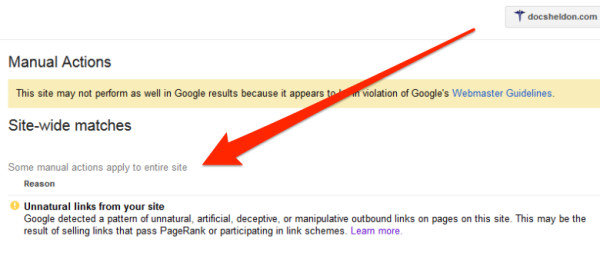
手动操作–如果在人工审核期间确定某个网页或网站违反了搜索引擎的网站站长指南,则可以实施手动操作,这会对排名产生不利影响。 这些操作可能会影响单个页面,也可能会应用于整个域。

元数据–这是一组数据,浏览器并不总是显示这些数据,浏览器会向搜索引擎提供有关页面上其他数据的信息。
ñ
Nofollow –有时,链接到准确性或质量可疑的资源可能被认为是必要的,甚至是有帮助的。 向超文本链接添加nofollow属性实质上是告诉搜索引擎您不保证目标页面。
Noindex –可以在文档的头部添加此元标记,以告诉搜索引擎不应允许该页面出现在搜索引擎结果页面(SERP)中。
Ø
随机-指不包含任何付费广告的搜索结果。
出站链接–位于网页上的链接,链接到在同一网站上找不到的页面。
P
PageRank –这是根据许多因素确定页面整体质量的一种计算,其中最重要的因素仍然被认为是入站链接。
熊猫–这是一种新的搜索算法,于2011年2月推出,专注于检测低质量或“稀薄”的内容。
企鹅–该算法于2012年4月推出,专注于入站链接的质量。
PBN –私人博客网络。 同一实体拥有的相互链接的网站。 某些PBN被认为具有操纵性,因为它们的存在是为了托管内容和链接,从而影响SERP。 一旦成为一种高效技术,这种网络避免检测就变得越来越困难。
[R
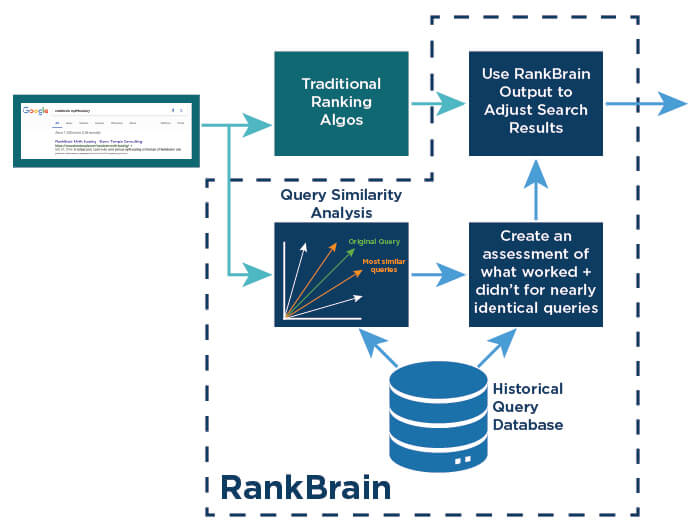
RankBrain –该算法已由Google在2015年10月确认,是一种机器学习算法,用于检查搜索引擎从未见过的搜索查询,并尝试将其与已知的查询相关联。
相互链接–两个不同站点上的两个网页故意链接在一起。 如果放置链接的唯一目的是影响网页排名的方式,则可以将大量的相互链接视为操纵性链接方案。
重定向–这是一种技术,通过该技术可以将指向目标URL的超链接重定向到另一个URL。 最常用的重定向是301(永久)和302(临时),尽管有些重定向很少使用。 (请参阅状态码)
响应式–网站设计的一种方法,可以调整显示元素的大小以适合查看该网站的设备的视口。 因此,可以轻松地从台式机,平板电脑或手机上查看和读取站点。
丰富的摘录–通过使用结构化数据标记(例如架构,微格式或属性中的资源描述框架(RDFa)),可以在SERP中显示网站内容的小样本,通常诱使更多用户点击该网站。
小号
模式–这是一种语义标记,涉及特定的本体,这些本体对对象进行分类并显示它们之间的关系。

Search Console (以前称为Google Webmaster工具)是Google提供的一套免费服务,用于检查索引编制状态并优化网站的可见性。
SERP –搜索引擎结果页。 响应搜索查询而提供的排名结果的网页。
服务器日志-服务器执行的所有操作的一个或多个自动生成的日志,通常有助于确定导致问题发生的原因。
服务器端包括–也称为SSI。 一种从另一个网页检索页面部分的方法。
附加链接–这些附加链接会显示在SERP的某些结果中,其中提供了许多内部链接,使用户可以更轻松地直接导航到感兴趣的网站部分。
Sitemap –网站内容的层次结构模型,通常以HTML格式构建,以帮助用户导航网站以将网站内容告知搜索引擎。
网站范围–是指在网站的每个页面(如侧边栏或页脚)中使用的链接和导航结构。
SSL –安全套接字层的缩写。 这是用于在客户端(浏览器或电子邮件客户端)和服务器之间建立加密管道的标准技术。
状态码–网络服务器响应浏览器调用给出的数字响应。 每个不同的数字代码表示不同的内容。
子域名–属于主域名的互联网域名。 例如,在URL https:// blog中。 searchengineland.com/ ,“博客”将是主域名searchengineland.com的子域。
Ť
分类法-这是指分类系统,对于多面导航(例如电子商务站点中通常存在的导航)尤其重要。
标题标签–创建网页标题的HTML,通常告诉人类和搜索引擎该页面的内容。 它位于网页的部分中,以及(通常)在搜索引擎中显示的自然结果。
TLD –顶级域。 这是TLD下所有域的一般分类。 例如,.com,.net,.org和.edu都是TLD,尽管现在还有许多其他顶级域名。
ü
UGC –用户生成的内容。 网页上的内容是由用户而非网站所有者或网站管理员创建的。 论坛和博客评论都是用户生成的内容的形式。
唯一身份访问者–在特定时间段内访问过一次网页的人(搜索者)。
URL –统一资源定位符。 有时称为网址。 对于此站点的主页,URL为https://searchengineland.com。 但是,这不是实际地址。 域名服务器将该URL转换为我们的IP地址208.80.6.139。
用户代理– Internet上的每个用户都有自己的用户代理,浏览器,客户端,爬网程序,甚至是提要阅读器和媒体播放器。 用户代理向服务器标识用户,服务器又通过其自己的用户代理将自己标识回用户。
V
垂直搜索–指一种特殊的搜索类型,可从特定区域返回结果。
Vlog –视频形式的博客。
w ^
网站站长指南–这些指南由搜索引擎发布,描述了搜索引擎认为可接受的行为和做法。 不遵守这些准则可能会导致排名下降或惩罚性行动。
白帽–通常认为这仅表示遵循已发布的《网站站长指南》认为可以接受的做法。
窗口小部件–提示用户采取行动或显示信息的图形用户界面而不是文本用户界面的元素。 它通常是一个独立元素,可以作为广告或交互式体验嵌入到网页中。 Google拒绝使用像这样的小部件作为linkbait:
X
XHTML –可扩展的超文本标记语言。 一种以XML语法重新构造HTML 4.0的语言。
XML –可扩展标记语言。 这种标记语言使用了与HTML不同的语法,并大大扩展了HTML可用的词汇表。
尽管上面列出的内容绝不是您在SEO冒险中会遇到的术语的详尽列表,但它们应该可以帮助您避免被大量的流行词所迷惑。 希望他们能解决您可能遇到的一些问题。
状态码
301 – URL已永久移动。 当您想要更改搜索结果中列出的网页的URL时,请使用301重定向。
302 –称为临时重定向。
403 –禁止。 即使请求有效,服务器也会拒绝操作。
404 –找不到。 找不到页面/资源。
503 –服务器因维护原因或请求过多而关闭,通常是临时状态。
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/10057.html