使用Apriori算法和BERT嵌入来可视化Search Console排名的变化
SEO面临的最大挑战之一就是重点。 我们生活在一个充满数据的世界中,这些数据具有各种工具,可以很好地完成各种工作,而其他工具则做得不好。 我们的数据来自我们的眼球,但是如何将大数据提炼成有意义的东西。 在这篇文章中,我将新旧结合在一起,以创建一种具有一定价值的工具,我们作为SEO一直都在做。 关键字分组和变更审核。 我们将利用一个鲜为人知的算法(称为Apriori算法)以及BERT,来生成有用的工作流程,以了解三万英尺处的有机可见性。
什么是Apriori算法
Apriori算法由RakeshAgrawal和RamakrishnanSrikant于2004年提出。它实质上是一种用于大型数据库的快速算法,用于查找数据行的组成部分之间的关联/共性,即事务。 例如,一家大型的电子商务商店可以使用此算法查找经常一起购买的产品,以便在购买套装中的另一种产品时它们可以显示关联的产品。
几年前,我从本文中发现了该算法,并立即发现了与帮助在大型关键字组中找到唯一模式集的联系。 从那以后,我们转向了语义驱动的匹配技术,而不是术语驱动的匹配技术,但这仍然是我第一次遍历大量查询数据时经常使用的算法。
| 交易次数 | ||||
| 1个 | 技术 | eo | ||
| 2 | 技术 | eo | 机构 | |
| 3 | eo | 机构 | ||
| 4 | 技术 | 机构 | ||
| 5 | 机车 | eo | 机构 | |
| 6 | 机车 | 机构 |
下面,我以Annalyn Ng的文章为灵感来重写Apriori算法支持的参数的定义,因为我认为它最初是通过直观的方式完成的。 我将定义与查询相关,而不是与超市交易相关。
支持
支持度是对术语或术语集受欢迎程度的衡量。 在上表中,我们有六个单独的标记化查询。 6个查询中有3个支持“技术”,即50%。 同样,“技术,搜索引擎优化”的支持率为33%,在6个查询中占2个。
置信度
置信度显示术语在查询中一起出现的可能性。 它写为{X-> Y}。 它简单地通过除以{术语1和术语2}支撑被支撑为{术语1}来计算。 在上面的示例中,{technical-> seo}的置信度为33%/ 50%或66%。
电梯
提升与置信度相似,但是解决了一个问题,即当根据简单的使用频率根据其他术语与其他术语一起出现的可能性进行计算时,真正的通用术语可能会人为地增加可信度得分。 升程的计算,例如,通过将支持{术语1和术语2}由(支撑为{术语1}倍支持{术语2})。 值为1表示没有关联。 大于1的值表示术语可能会一起出现,而小于1的值表示它们不太可能一起出现。
使用Apriori进行分类
对于本文的其余部分,我们将继续介绍Colab笔记本和随附的Github存储库,其中包含支持笔记本的其他代码。 可在此处找到Colab笔记本。 Github存储库称为QueryCat。
我们从Google Search Console(GSC)的标准CSV开始,对28天的比较查询进行了一段时间的比较。 在笔记本中,我们加载Github存储库,并安装一些依赖项。 然后,我们导入querycat并加载包含GSC输出数据的CSV文件。
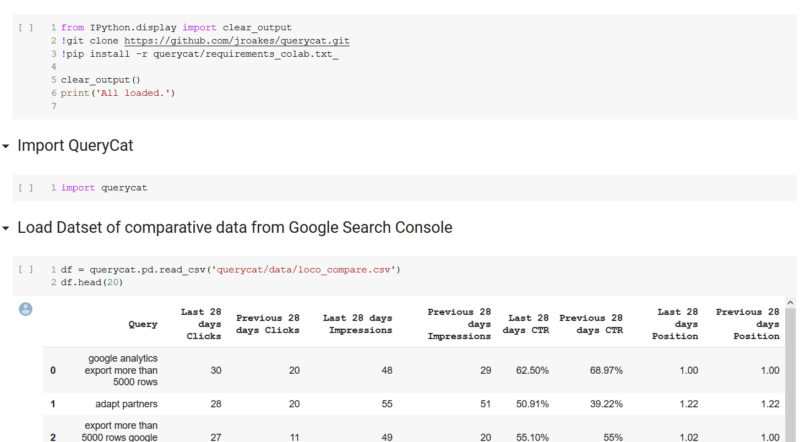
现在我们有了数据,我们可以在querycat中使用Categorize类,以传递一些参数并轻松找到相关的类别。 要查看的最有意义的参数是“ alg”参数,该参数指定要使用的算法。 我们包括了Apriori和FP-growth,它们都具有相同的输入且具有相似的输出。 FP-Growth算法被认为是一种更有效的算法。 在我们的用法中,我们首选Apriori算法。
要考虑的另一个参数是“最小支持”。 这实质上是要考虑术语在数据集中出现的频率。 该值越低,您将拥有更多的类别。 较高的数字,较少的类别,通常没有类别的查询更多。 在我们的代码中,我们指定没有计算类别的查询,类别为“ ## other ##”
其余参数“ min_lift”和“ min_probability”处理查询分组的质量,并赋予这些词一起出现的概率。 它们已经设置为我们找到的最佳常规设置,但是可以根据个人喜好在较大的数据集上进行调整。
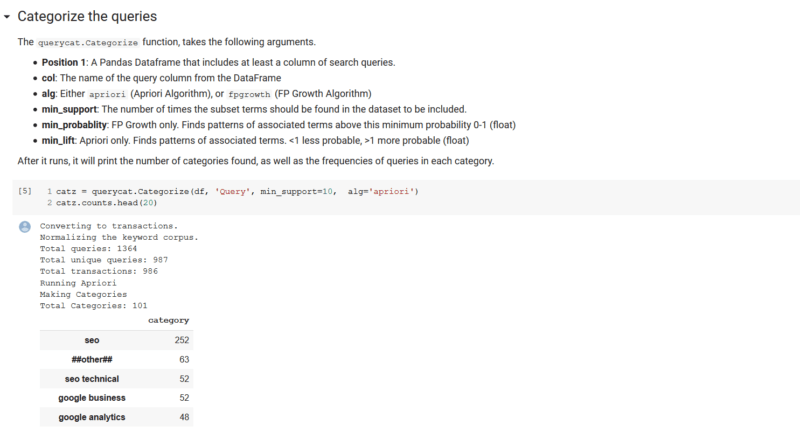
您可以看到,在我们总共1,364个查询的数据集中,该算法能够将查询分为101个类别。 还要注意,该算法能够选择多词短语作为类别,这是我们想要的输出。
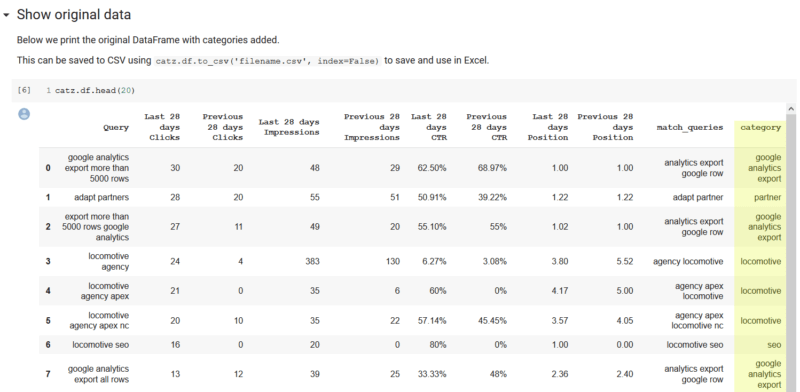
运行此命令后,您可以运行下一个单元格,该单元格将输出原始数据,并在每行后附加类别。 值得注意的是,这足以将数据保存到CSV,能够按Excel中的类别进行透视并按类别汇总列数据。 我们在笔记本中提供了一条注释,描述了如何执行此操作。 在我们的示例中,我们仅在几秒钟的处理中就提取了匹配的有意义的类别。 此外,我们只有63个不匹配的查询。

现在有了新的(BERT)
客户和其他利益相关者经常问的一个问题是“最近的<插入时间段在这里发生了什么?” 借助一点熊猫魔术和我们已经处理的数据,到目前为止,我们可以轻松地按类别比较数据集中两个时段的点击次数,并提供一列显示差异的列(或者您可以进行%更改如果您愿意)在两个期间之间。
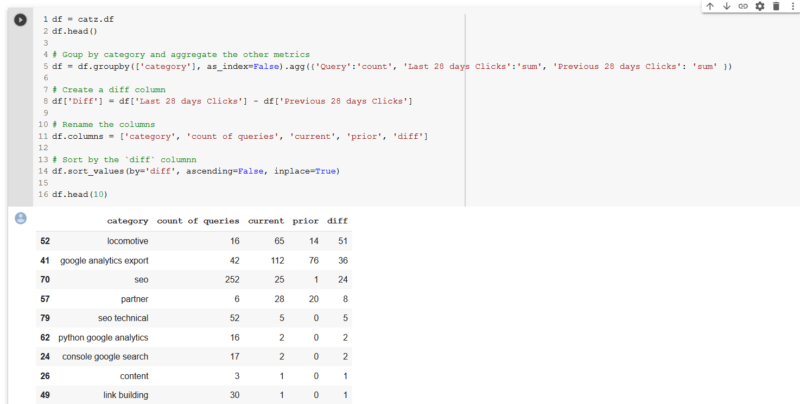
由于我们刚刚在2019年底推出了新域名locomotive.agency,因此毫无疑问,大多数类别在这两个时期内均显示点击量增长。 我们也很高兴看到我们的新品牌“机车”取得了最大的增长。 我们还看到,我们在Google Analytics(分析)导出上撰写的一篇文章有42个查询,并且每月增加36次点击。
这很有用,但是看看在我们做得更好或更坏的查询类别之间是否存在语义关系会很酷。 我们是否需要围绕某些类别的主题建立更多的主题相关性?
在共享代码中,我们通过出色的Huggingface Transformers库轻松地访问了BERT,只需在代码中包含querycat.BERTSim类即可。 我们不会详细介绍BERT,因为Dawn Anderson在这里做得很好。
此类允许您输入带有“条件(查询)”列的任何Pandas DataFrame,它将加载DistilBERT,并将其处理为相应的汇总嵌入。 嵌入本质上是数字的向量,其保持模型对各种术语的“学习”含义。 在运行querycat.BERTSim的read_df方法之后,术语和嵌入分别存储在术语(bsim.terms)和embeddings(bsim.embeddings)属性中。
相似
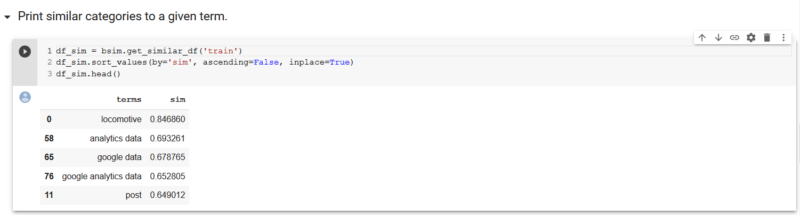
由于我们在带有嵌入的向量空间中进行操作,因此这意味着我们可以使用余弦相似度来计算向量之间角度的余弦值,以测量相似度。 我们在此处提供了一个简单的功能,这对于可能具有数百到数千个类别的网站很有用。 “ get_similar_df”将字符串作为唯一参数,并返回与该术语最相似的类别,相似度得分为0到1。您可以在下面看到,对于给定的术语“ train”,机车,我们的品牌,是最接近的类别,相似度为85%。
绘图变化
回到我们的原始数据集,至此,我们现在有了一个包含查询和PoP更改的数据集。 我们已经通过BERTSim类运行了查询,因此该类从我们的数据集中了解术语和嵌入。 现在,我们可以使用精彩的matplotlib,以有趣的方式将数据栩栩如生。
调用一个名为diff_plot的类方法,我们可以在二维语义空间中绘制类别视图,并在气泡的颜色(绿色是增长)和大小(变化的幅度)中包含点击变化信息。
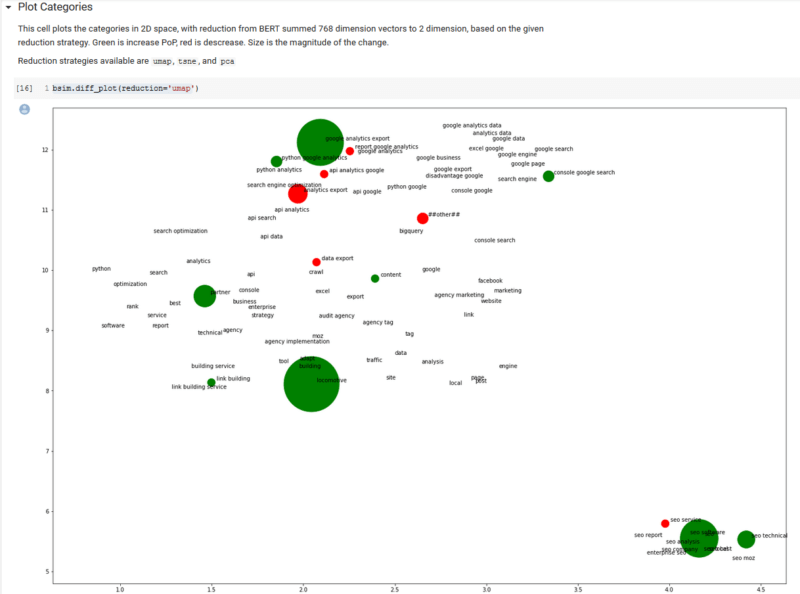
我们包括了三种单独的降维策略(算法),这些策略将BERT嵌入的768维降低为二维。 算法是“ tsne”,“ pca”和“ umap”。 我们将留给读者研究这些算法,但是“ umap”具有质量和效率的良好结合。
除了有机会更深入地介绍Google Analytics(分析),很难(因为我们是一个相对较新的网站)从地块中看到很多信息。 同样,如果我们删除了零变化,这将是一个更具信息性的情节,但我们想展示该情节如何以有意义的方式在语义上对主题类别进行聚类。
包起来
在本文中,我们:
- 引入了Apriori算法。
- 展示了如何使用Apriori快速分类来自GSC的一千个查询。
- 显示了如何使用类别按类别汇总PoP点击数据。
- 提供了一种使用BERT嵌入查找语义相关类别的方法。
- 最后,显示了最终数据的图,该图显示了按语义类别定位的增长和下降。
我们已将所有代码作为开源提供,希望其他人可以发挥和扩展功能,并撰写更多文章来展示其他各种算法(新旧算法)可以帮助我们理解周围的数据。
今年的SMX Advanced将为开发人员提供全新的SEO,并通过高科技课程(许多采用实时编码格式)进行跟踪,重点是使用代码库和体系结构模型来开发可改善SEO的应用程序。 SMX Advanced将于6月8日至10日在西雅图举行。 立即注册。
本文表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/10292.html