通过日志分析可以回答的7个基本技术SEO问题(以及如何轻松实现)
日志分析已发展成为技术SEO审核的基本部分。 服务器日志使我们能够了解搜索引擎爬网程序如何与我们的网站进行交互,并且对服务器日志的分析可以导致您可能没有搜集到的可行的SEO见解。
第一:选择工具
有许多工具可用于帮助进行服务器日志分析,哪种工具最适合您取决于您的技术知识和资源。 您将要考虑三种类型的日志文件分析工具(除非您是从命令行执行的,否则,如果您还没有经验,我不建议您这样做):
电子表格
如果您了解绕过Excel的方式(如果创建数据透视表并使用VLOOKUP是您的第二天选择),则可以通过执行BuiltVisible本指南中显示的步骤来使Excel发挥作用。
同样重要的是要注意,即使您使用其他工具选项之一,有时也需要将收集的数据导出到Excel中。 这会将数据输出为易于集成或与其他数据源(例如Google Analytics(分析)或Google Search Console)进行比较的格式。
您是在整个分析中使用Excel还是只在最后使用Excel,取决于您要花费多少时间来使用它来筛选,细分和组织数据。
开源工具
如果您没有预算来购买工具,但是您确实拥有配置这些工具的技术资源,那么这就是您的选择。 最受欢迎的开源选项是Elastic的ELK堆栈,其中包括Kibana,Elasticsearch和Logstash。
付费工具
如果您没有技术支持或资源,那确实是最好的选择,尤其是因为这些工具的设置非常简单。 如果您需要手动上传日志文件(而不是直接连接到服务器进行监视),则一些选项还支持cURL:
- 尽管Splunk不是最便宜的选择,但它可能是市场上最著名的付费日志分析器。 但是,它有一个免费的简易版,您可能想签出。
- Logz.io提供ELK即服务(基于云),已将SEO视为其用例之一,并且也有免费选项。
- Loggly还提供了有限的免费版本。 在尝试了其他程序之后,这是我目前使用的程序,它是您在整个文章的屏幕快照中都会看到的程序。 Loggly位于云中,我非常喜欢它易于使用的界面,该界面有助于轻松进行过滤和搜索。 此功能使我可以节省分析时间,而不用对数据进行分段和过滤。
为案例选择最佳工具后,就该开始分析了。 您将要确保将分析重点放在可操作的SEO项目上,因为在非SEO导向的环境中很容易迷失方向。
以下是一些有助于我进行日志分析的问题,以及如何轻松回答这些问题(在我的情况下,使用Loggly)。 我希望这将使您看到如何也能以非痛苦的方式浏览日志并为您自己的SEO流程进行分析。
1.哪些漫游器访问您的网站? 寻找堵塞物或刮板。
日志遵循预定义的格式。 如下面的屏幕快照所示,使用预定义的日志字段过滤器,可以在Loggly中更轻松地识别用户代理。
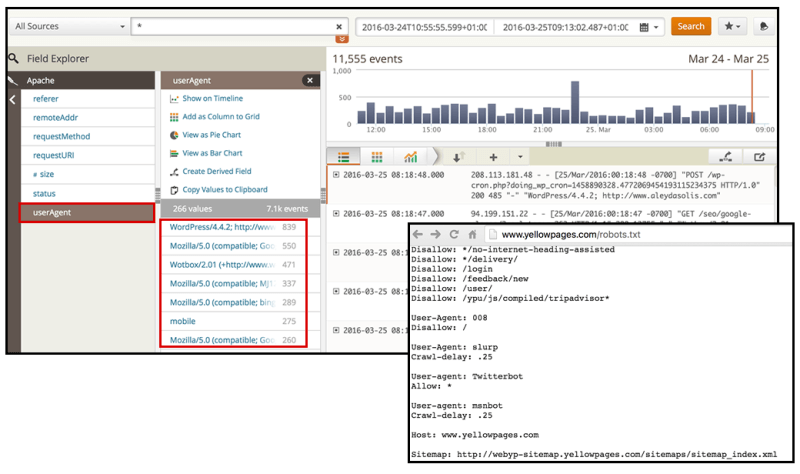
[点击放大]
首次开始进行日志分析时,不仅要检查搜索机器人(例如Googlebot,bingbing或Yandex bot)的活动,而且还要检查可能产生性能问题,污染分析的潜在垃圾邮件,这可能是值得的并抓取您的内容。 为此,您可能需要与一系列已知的用户代理进行核对,例如该代理。
寻找可疑的漫游器,然后分析其行为。 他们随着时间的活动是什么? 在选定的时间段内,他们发生了多少事件? 它们的出现是否与性能或分析垃圾邮件问题相吻合?
在这种情况下,您可能不仅要禁止在robots.txt文件中使用这些bot,还希望通过htaccess阻止它们,因为它们通常不会遵循robots.txt指令。
2.您所有的目标搜索引擎机器人都在访问您的页面吗?
一旦确定了到达您网站的漫游器,就该关注搜索引擎漫游器,以确保它们能够成功访问您的页面和资源。 使用Loggly中的“ userAgent”过滤器,您可以直接选择要分析的对象,或者使用布尔运算符通过搜索功能按名称搜索它们。
筛选以仅显示您感兴趣的搜索引擎机器人后,您可以选择图表选项以直观地观察其活动。 哪些搜索引擎在您网站上的活动水平最高? 它们是否与您要排名的搜索引擎一致?
例如,在这种情况下,我们可以看到其中一个Googlebots的活动是其中一个Bingbots的两倍,并且在3月24日22:30h出现了特定的峰值。
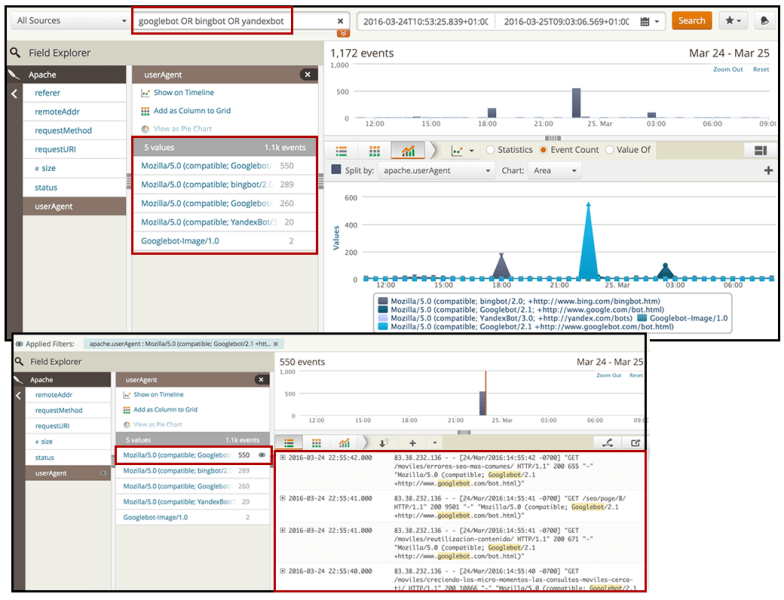
[点击放大]
在这里重要的不仅是搜索bot来到您的网站,而且他们实际上是在花时间爬网正确的页面。 他们正在爬行哪些页面? 这些页面的HTTP状态如何? 搜索漫游器是在爬行相同页面还是在不同页面?
您可以选择要检查的每个搜索用户代理,然后导出数据以使用Excel中的数据透视表进行比较:
基于这些初始信息,我们将开始更深入地研究,以不仅验证这些机器人在爬网行为方面的差异,还可以验证它们是否确实在爬网到应该的位置。
3.哪些页面不能正确提供? 查找具有3xx,4xx和5xx HTTP状态的页面。
通过搜索所需的搜索机器人(在本例中为Googlebot),然后选择“状态”过滤器,可以选择要分析的页面的HTTP值。
我建议您查找状态代码为3xx,4xx和5xx的代码,因为您想查看要提供给搜寻器的重定向页面或错误页面。
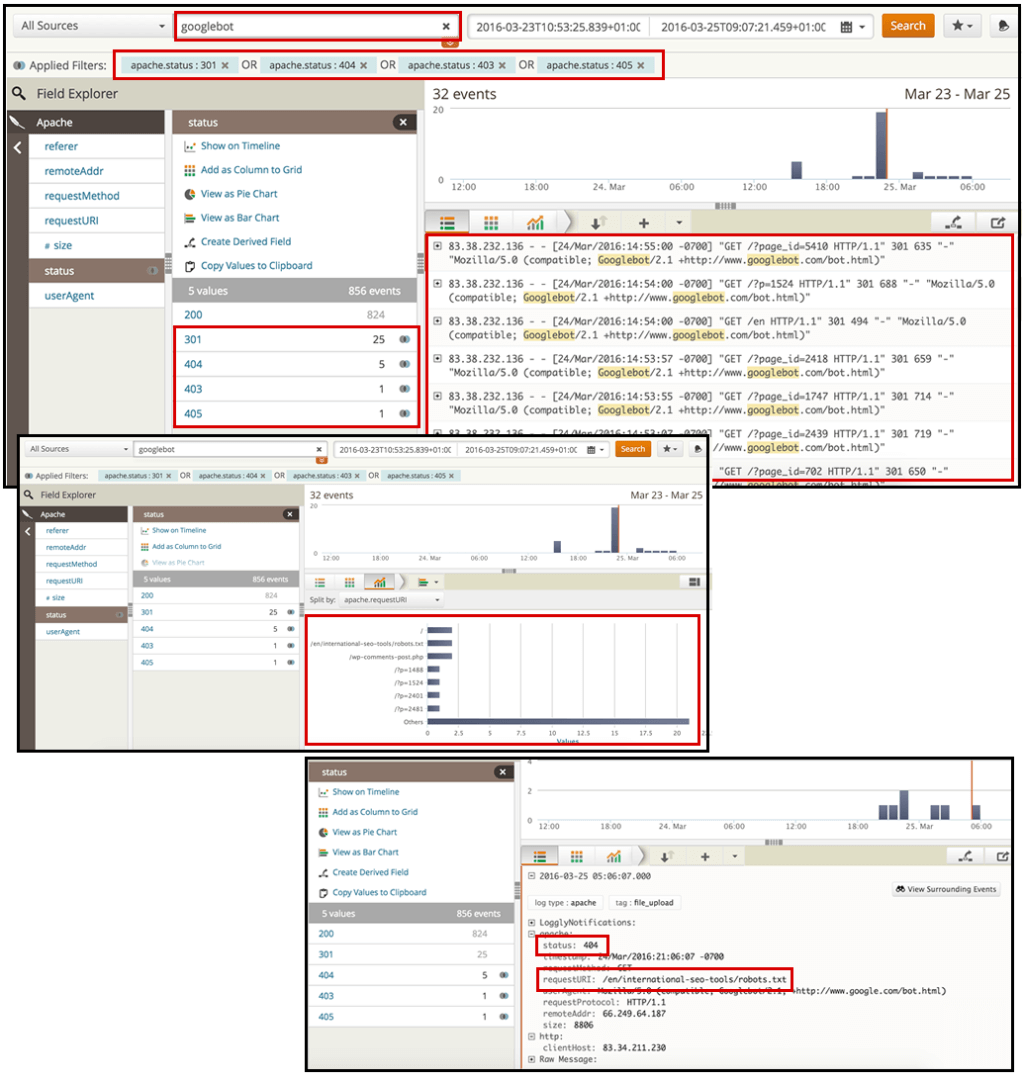
[点击放大]
在这里,您可以识别出生成大多数重定向或错误的首页。 您可以导出数据并将这些页面的优先级固定在SEO建议中。
4.每个搜索漫游器抓取最多的页面是什么? 验证它们是否与您的站点最重要的站点一致。
搜索所需的搜索机器人时,可以直接选择“ requestURI”过滤器,以获取该机器人正在请求的顶级Web文档的列表,无论是资源还是页面。 您可以直接在界面中查看它们(例如,以验证它们的HTTP状态为200),也可以将它们导出到Excel文档中,在其中可以确定它们是否与高优先级页面一致。
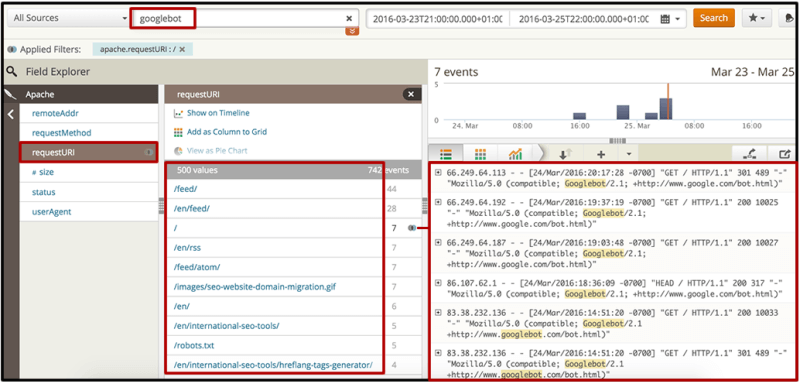
[点击放大]
如果您最重要的页面不在搜索的顶部页面中(或更糟糕的是,根本不包括在内),则可以在SEO建议中决定适当的操作。 您可能想要改善到这些页面的内部链接(无论是从主页还是从您标识的某些顶级爬网页面),然后生成并提交新的XML网站地图。
5.搜索漫游器是否在爬行他们不应该搜索的页面?
您还将需要识别不打算被索引因此不应被爬网的页面和资源。
再次使用“ requestURI”过滤器来获取所需的bot所请求的页面的顶部列表,然后导出数据。 检查您通过robots.txt阻止的页面和目录是否确实在被爬网。
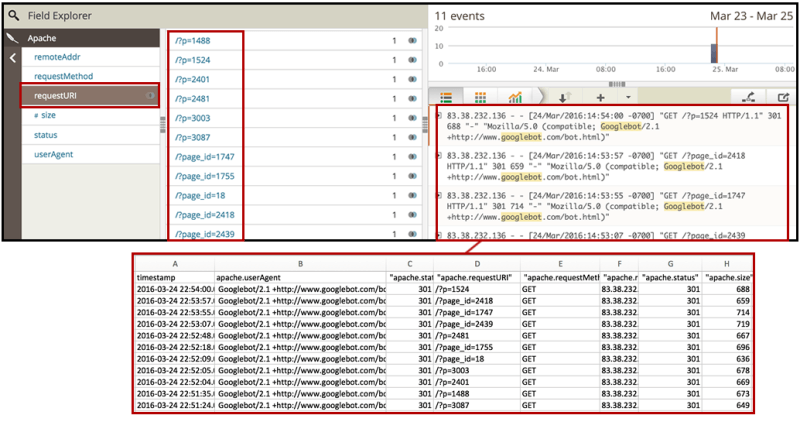
[点击放大]
您还可以检查未被robots.txt阻止但从爬网角度来看不应优先的页面-包括未索引,规范化或重定向到其他页面的页面。
为此,您可以使用自己喜欢的SEO搜寻器(例如Screaming Frog或OnPage.org)从导出的列表中进行列表搜寻,以添加有关其元机器人noindexation和规范化状态的附加信息,以及您所使用的HTTP状态从日志中已经有。
6.随着时间的推移,您的Googlebot抓取速度是多少?它与响应时间和投放错误页面的关系如何?
不幸的是,可以通过Google Search Console的“抓取统计信息”报告获取的数据过于笼统(不一定足够准确),无法采取行动。 因此,通过分析自己的日志以识别一段时间内的Googlebot抓取速度,您可以验证信息并将其细分以使其可操作。
使用Loggly,您可以选择在折线图中以所需的时间范围查看Googlebot的活动,在该图中可以独立显示HTTP状态以验证一段时间内的峰值。 了解什么类型的HTTP请求以及何时发生,将显示是否触发了错误或重定向,这可能会导致Googlebot产生无效的抓取行为。
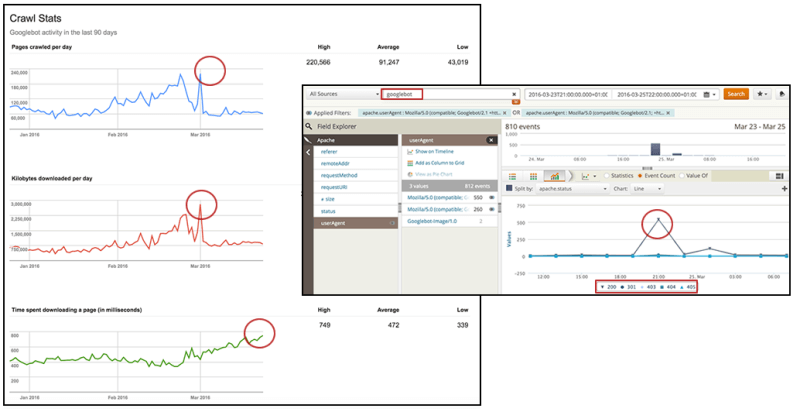
[点击放大]
您可以通过在期望的时间段内绘制Googlebot请求的文件大小来进行类似操作,以识别爬网行为更改是否相关,然后可以采取适当的措施来优化它们。
7. Googlebot用来抓取您的网站的IP是什么? 验证他们在每种情况下都正确地访问了相关的页面和资源。
我专门为那些向不同位置的用户提供不同内容的网站而提供了这一内容。 在某些情况下,此类网站在不知不觉中为使用其他国家/地区的IP的抓取工具提供了糟糕的体验-从完全阻止它们到允许他们仅访问内容的一个版本(防止它们抓取其他版本)。
Google现在支持可感知区域设置的爬网,以发现专门针对其他国家/地区的内容,但是,确保所有内容都得到爬网仍然是一个好主意。 如果不是,则表明您的网站配置不正确。
在按用户代理进行细分之后,您可以按IP进行过滤,以验证该网站是否为来自相关国家/地区的抓取工具提供了正确的每个页面版本。
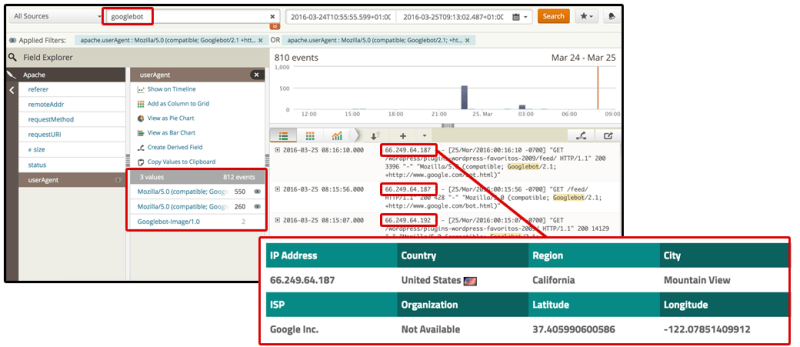
[点击放大]
例如,看看当我尝试使用西班牙IP访问www.nba.com上的NBA网站时发生了什么—我从AS网站(西班牙本地体育报纸)重定向到302篮球的子域,如下面的屏幕截图所示。
当我从法国IP输入时,也会发生类似的情况。 我得到302重定向到法国当地体育报纸L'Equipe的篮球子目录。
过去我曾解释过为什么我不喜欢具有国际针对性的自动重定向。 但是,如果出于业务(或任何其他)原因而存在它们,那么对来自同一国家/地区的所有抓取工具(搜索机器人和任何其他用户代理)赋予一致的行为非常重要,请确保SEO最佳做法是在每种情况下都紧随其后。
最后的想法
我希望仔细研究这些问题,并解释如何使用日志分析来回答这些问题,将有助于您扩大和加强您的SEO技术工作。
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/9640.html