逐步执行手动反向链接审核

这可能是每个SEO最不喜欢的工作:反向链接审核。 这不是因为工作本身很可怕(尽管在链接占用量较大的站点上可能很乏味),而是因为当域出现问题时几乎总是执行该工作。
无论您是因为正在寻找新策略的SEO还是正在受到基于链接的惩罚的网站所有者而正在阅读本文,我希望您发现以下方法对您有所帮助。
在继续之前,我应该注意,我更喜欢健壮的数据集,因此在示例中将使用四个链接数据集。 他们是:
- Google Search Console
- 雄伟
- Ahrefs
- 莫兹
尽管我已经使用上述所有工具付款(除了Search Console,该工具是免费的),但每种工具都提供了一种免费获取数据的方法-通过试用帐户或网站所有者的免费数据。 您还可以使用其他链接源,例如Spyfu或SEMrush,但是以上四个结合在一起往往会捕获您的反向链接数据中的绝大部分。
现在,让我们开始...
提取数据
该过程的第一步是从上面列出的来源中提取数据。 下面,我将概述每个平台的过程。
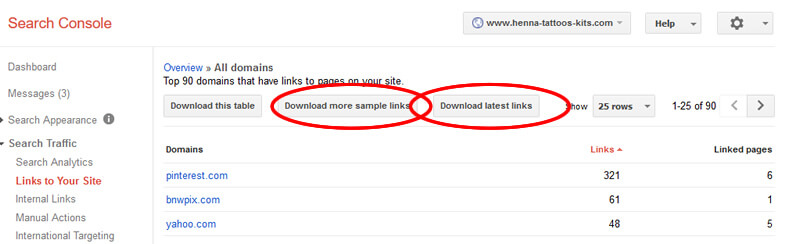
Google Search Console
- 登录后,选择要从中下载反向链接的属性。
- 在左侧导航栏中的“搜索流量”下,单击“指向您的网站的链接”。
- 在“谁链接最多”列下,单击“更多”。
- 单击按钮“下载更多示例链接”和“下载最新链接”,然后将每个CSV保存到文件夹。
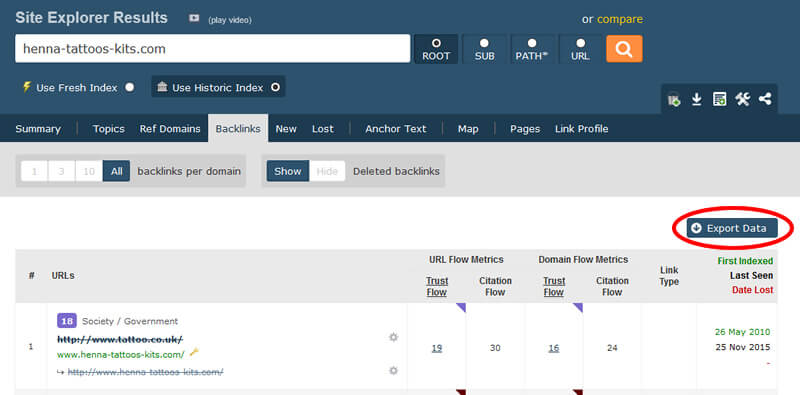
雄伟
- 如果您没有帐户,请创建一个帐户,因为您需要该帐户来导出数据。 如果您想要访问的只是自己网站的数据(这就是我们想要的),他们将为您提供免费的访问权限。 您可以在https://majestic.com/account/register上找到有关此信息的更多信息。 这些说明的其余部分将遵循付费帐户的过程,但是它们基本上是相同的。
- 在搜索框中输入您的域。
- 点击结果上方的“反向链接”标签。
- 在选项中,确保已为“每个域的反向链接”和“使用历史索引”(而不是“使用新鲜索引”)选择了“全部”。
- 单击“导出数据”,然后将文件保存到之前创建的文件夹中。
- 如果您有大量数据,系统将指导您创建“高级报告”,然后在其中需要创建“域报告”。
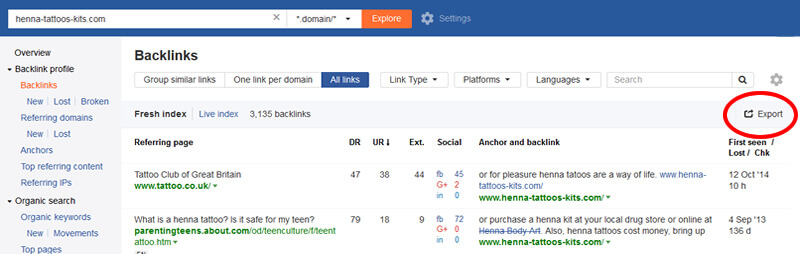
Ahrefs
- 如果您没有帐户,则可以注册免费试用。
- 在搜索框中输入您的域。
- 点击左侧导航顶部的“反向链接”。
- 在结果上方的选项中选择“所有链接”。
- 单击“导出”,然后将文件保存到之前创建的文件夹中。
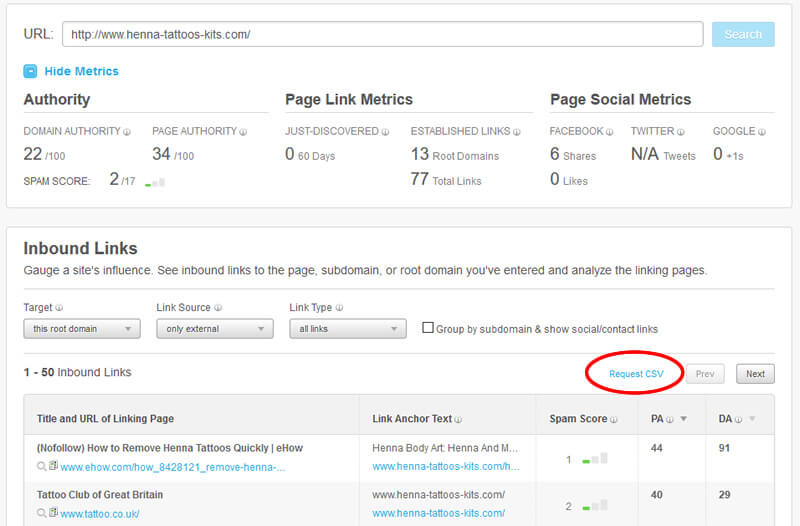
莫兹
- 如果您没有帐户,请注册免费试用以获取完整数据。
- 在主页上,单击顶部导航中的“ Moz工具”,然后在下拉菜单中单击“查看所有Moz产品”。
- 在结果页面上单击“打开站点资源管理器”。
- 在“ URL”字段中输入您的域。
- 在结果上方的选项中,选择目标下的“此根域”。
- 点击“请求CSV”,然后在可用时将其保存到与其他文件相同的文件夹中。
整理数据
接下来,我们需要通过将所有反向链接收集到一个列表中并过滤掉已知的重复项来对数据进行条件处理。 您下载的每个电子表格都略有不同。 这是您正在查看的内容:
- Google Search Console。 您将从Search Console中获得两个电子表格。 同时打开它们,然后将每个第一列中的所有URL**到新的电子表格中,删除标题行。 两者都将依次进入A列。
- 雄伟。 在Majestic下载中,您将在B列中找到链接源URL。您将希望将所有这些URL**到将Search Console链接**到的同一电子表格中。 为此,您需要将Majestic数据直接插入A列中Search Console数据的下方。
- Ahrefs。 Ahrefs将源URL放在D列中。将所有这些URL**到新的电子表格中,再次在A列中,就在您已添加的链接的正下方。
- 莫兹Moz将源URL放在A列中。再次将所有这些URL**到新电子表格的A列中,直接位于您输入的其他数据下方。
现在,您应该在新电子表格的A列中有来自所有四个来源的所有反向链接的列表。 然后,您将选择A列,单击顶部的“数据”选项卡(假设您在Excel中工作),然后单击“删除重复项”。 这将删除在各种数据源之间重复的链接。
下一步是选择所有剩余的数据行并将它们**到记事本文档中,然后将文档保存在易于引用的位置。
现在有趣的部分是
现在,您已获得所有入站反向链接的列表,但这并不是特别有用。 接下来我们要做的是为他们收集统一的数据。 这就是URL Profiler的来源。对于这一步,您必须下载URL Profiler。 像到目前为止我提到的其他工具一样,URL Profiler可以免费试用。 因此,如果是一次性的,则可以坚持试用。
一旦下载并安装,就会有一些设置过程可以帮助您快速分析。 您需要做的第一件事是单击“帐户”菜单,该菜单将弹出窗口,从前面讨论的各种工具中输入API密钥。
有用的是,每个选项卡都为您提供了有关获取各种API密钥的分步说明的链接,因此在此不再赘述。 这使我得以发挥出色……
现在,您将看到一个如下所示的屏幕:
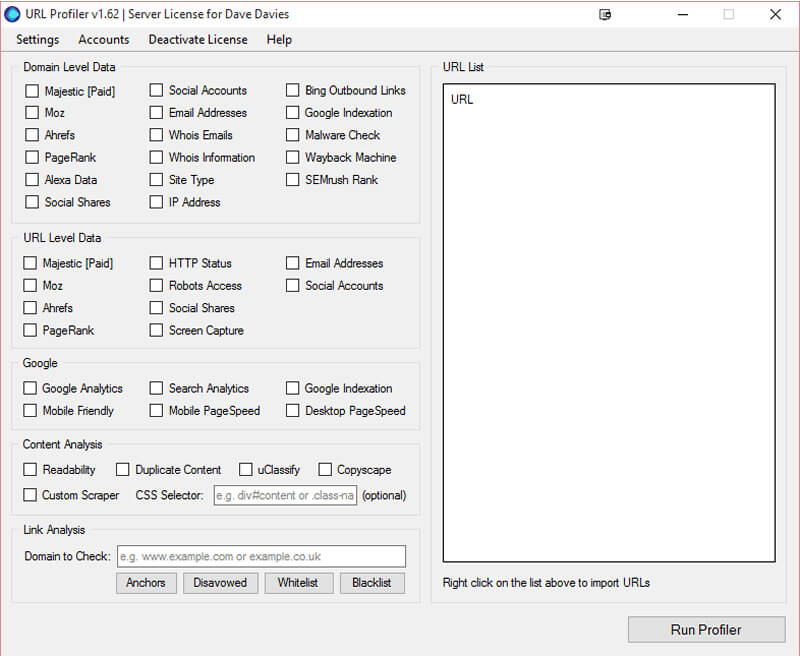
第一步是右键单击右侧的大而空的URL列表框,然后选择“从文件导入”。 在此处,选择使用上面电子表格中的链接创建的记事本文档。
现在,您将在框中看到所有反向链接的列表,并且需要从左侧的框中选择要收集的所有数据。 您想要的数据越多,花费的时间就越长,但是您必须除掉更多的数据-因此,您通常只希望选择与手头任务相关的数据。 当我寻找低质量的链接时,我倾向于选择以下内容:
域级数据
- 雄伟[付费]
- 莫兹
- Ahrefs
- 社会分享
- 网站类型
- IP地址
URL级数据

- 雄伟[付费]
- 莫兹
- Ahrefs
- HTTP状态
- 社会分享
在底部的“链接分析”字段中,您将输入您的域。 这将为您提供类似于以下屏幕:
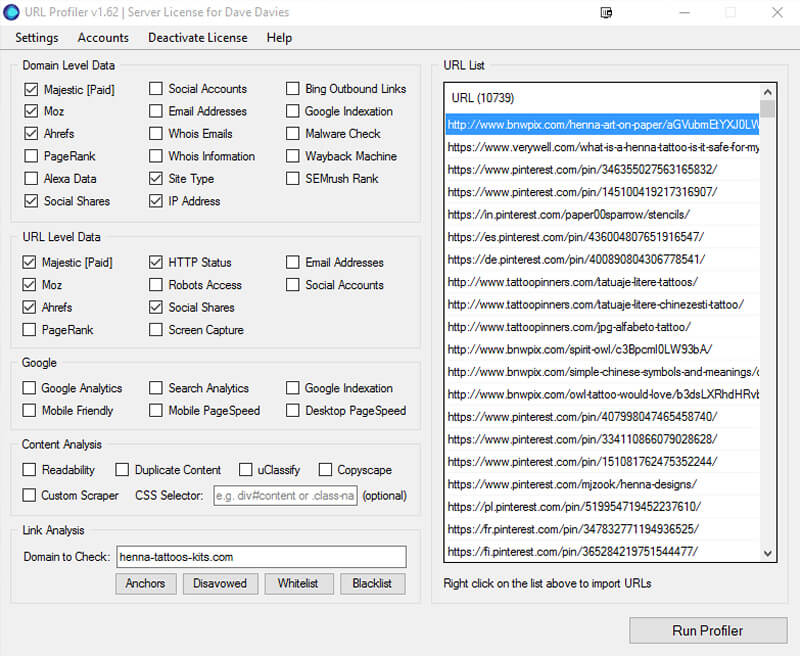
点击“运行Profiler”。 在此阶段,您可以去喝杯咖啡。 您的计算机代表您而努力工作。 如果您没有大量的RAM,并且有很多要爬网的链接,则它会使事情陷入困境,因此可能需要一些耐心。 如果您有很多事情要做,建议您隔夜或在专用于该任务的计算机上运行它。
完成后,您将获得一个包含链接的电子表格。 在这里,将来自所有反向链接源的所有数据组合在一起,然后统一使用它们所拥有的信息,便会获得回报。
因此,让我们继续进行最后一步...
执行反向链接审核
URL Profiler完成后,您可以打开包含结果的电子表格。 它看起来像这样:
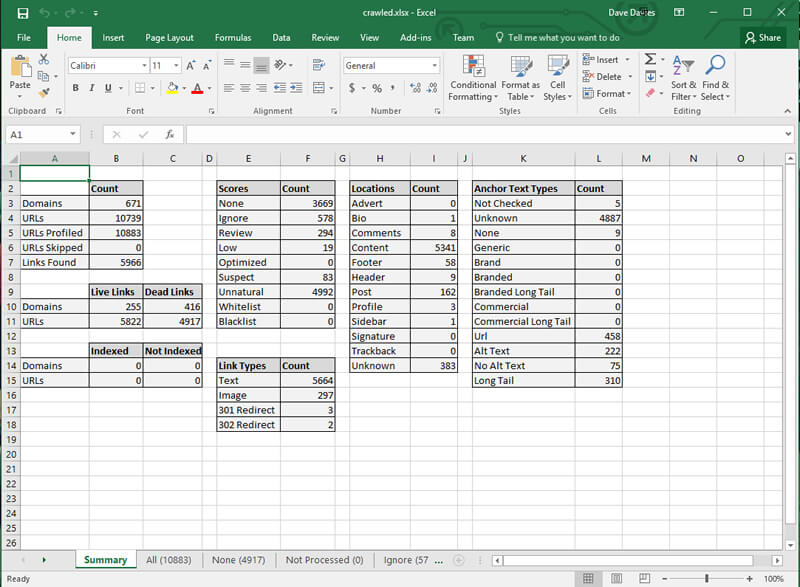
现在,我要做的第一件事是删除除“所有”以外的所有选项卡。 我喜欢收集数据的工具,但我不喜欢自动评分系统。 我还希望获得视觉效果,即使是在我将要移回到该阶段要删除的类似标签的项目上(更多内容,请参见下文)。
删除这些多余的选项卡后,您将获得一个包含所有反向链接和统一数据的电子表格。 下一步是删除您不想使电子表格混乱的列。 它会足够宽,没有额外的列。
尽管您选择保留的列将具体取决于您要查找的内容(以及您决定包括的数据),但我倾向于发现以下内容对全局有所帮助:
- 网址
- 服务器国家
- IP地址
- IP域
- HTTP状态代码(如果您不知道代码,则为HTTP状态)
- 网站类型
- 连结状态
- 链接分数
- 目标网址
- 锚文字
- 链接类型
- 链接位置
- Rel Nofollow
- 领域雄伟引文流
- 领域雄伟的TrustFlow
- 域Mozscape域授权
- 域Mozscape页面授权
- 域Mozscape MozRank
- 域Mozscape MozTrust
- 域Ahrefs排名
- URL Majestic CitationFlow
- URL Majestic TrustFlow
- URL Mozscape页面授权
- 网址Mozscape MozRank
- 网址Mozscape MozTrust
- URL Ahrefs排名
- 网址Google Plus Ones
- URL Facebook喜欢
- URL Facebook分享
- URL Facebook评论
- 网址Facebook总计
- URL LinkedIn分享
- URL Pinterest引脚
- URL总份额
对于那些曾经取笑我的人来说,我的办公桌看起来像是……
……现在你知道为什么了! 虽然可以在单个监视器上使用,但需要大量滚动。 如果您有大量反向链接,建议至少使用两台显示器(最好是三台)。 但这取决于您。
现在,回到对所有这些反向链接行的处理。
第一步是创建三个新选项卡。 我将其命名为: nofollow , nolink和nopage。
- 第一步:按HTTP状态排序,然后删除不产生200代码的行。 本质上,这些页面曾经存在并且不再存在。 我偶尔会通过URL Profiler再次运行它们,以确保站点不会暂时关闭,但是对于大多数用途而言,这不是必需的。 将它们移到Excel文档中的“ nopage”表中。
- 第二步:按链接状态排序。 我们只需要实际找到的链接。 数据库(尤其是Majestic的历史数据库)将保存任何具有指向您链接的URL。 如果该链接已删除,那么您显然不想在审核过程中考虑它。 将它们移至“ nolink”选项卡。
- 第三步:按Rel Nofollow排序。 在大多数情况下,您无需花时间在nofollowed链接上,因此最好将它们从要处理的数据中删除。 将它们移到“ nofollow”。
在此示例中,我使用的网站是从10,883行链接开始的。 经过这三个步骤,我剩下了5,393。 现在,我只有不到一半的链接需要整理。
处理剩余数据
现在,您如何处理数据将取决于您要寻找的内容。 我不可能在这里列出所有各种用例,但是以下是一些常用的排序系统,我可以使用它们来加快审阅过程并减少尝试查找不自然链接时需要访问的单个页面的数量:
- 首先按锚文本排序,然后按URL排序。 这将为您提供锚文本过度使用的非常坚实的画面。 在您看到大量使用特定锚点或可疑锚点(“发薪日贷款”,有人吗?)的地方,您知道需要重点关注那些锚点并查看链接。 通过对域进行第二次分组,您不会偶然访问同一域的100个链接,而只是为了做出相同的决定。 这也将使现场运行问题更加明显。
- 首先按IP上的域排序,然后按URL排序。 这将使您快速了解反向链接配置文件是否属于低端链接方案的一部分。 如果您购买了便宜的链接,则可能要从此链接开始。
- 首先按网站类型排序,然后按Majestic,Ahrefs或Moz得分排序。 我将由您自己决定,您对自己的信任度会更高,尽管不应将其视为福音。 这些分数基于一些非常聪明的人(而不是Google)构建的算法。 就是说,如果您在这三个方面都取得了不错的成绩,则至少可以在了解该信息的情况下查看该网站。
在我查看(并且在访问链接之前)的过程中,我倾向于扫描各个分数,URL和链接位置的社交份额。 这将告诉我很多有关可能找到的东西以及可能找到的地方的信息。
随着时间的流逝,您将开发出需要访问哪些链接以及不需要访问哪些链接的直觉。 我倾向于查看的内容可能比我需要的更多,但是我经常发现自己从事链接惩罚审核,因此勤奋是关键。
如果您只是想定期查看反向链接以确保其中没有问题,则可以跳过更多的手动查看,并根据数据做出更多决策。
结论
进行任何类型的审核的关键是收集可靠的数据,并将其放置在尽可能易于消化和使用的格式中。 尽管这些电子表格中有很多数据要处理,但要处理的数据就更少了,您将没有完整的图片。
尽管此过程不是自动化的(如您现在所知),但它极大地加快了进行反向链接审核的过程,减少了您在任何特定页面上判断链接所花费的时间(感谢开发人员添加中的“链接位置”,并可以更快地进行批量决策。
例如,在简单的按URL排序中,由于目录质量低下的一些重大技术问题,我快速浏览了该列表并发现directory.askbee.net链接了4,342次。 现在,我们有1,051个要解决的链接。
同样,每种需求都需要使用不同的筛选器,但是当您根据需要完成的工作进行不同的排序时,您会很快发现手动反向链接审核虽然费时又费时,但并非噩梦经常看起来。
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/9648.html