9个Screaming Frog和DeepCrawl中不容错过的抓取报告,涵盖了严重的SEO攻击

过去,我已经写了大量有关使用各种爬网工具来帮助SEO的文章。 原因很简单。 根据我已完成的审核次数,我想说,直到您抓取它,您才真正了解大型复杂网站的状况。
对于爬网网站,我最喜欢的两个工具是DeepCrawl(我在客户咨询委员会的位置)和Screaming Frog。 两者都是具有重要功能的出色工具。
我通常使用DeepCrawl进行企业级爬网,而在中小型网站上使用Screaming Frog。 由于企业爬网有时会产生一些较小的外科爬网,因此我也将两者结合使用。 因此,对我而言,将DeepCrawl与Screaming Frog结合起来的总和大于其部分:1 + 1 = 3。
两种工具都提供了大量数据,但是我发现阴影中存在一些强大而重要的报告。 在这篇文章中,我将快速介绍九个容易错过的抓取报告,这些报告包含了严重的SEO冲击。 其中有两个报告是DeepCrawl 2.0的一部分,该报告应尽快发布(在接下来的几周内)。 让我们开始。
隐藏的青蛙:容易错过,但功能强大,《尖叫的青蛙》报道
重定向链
大多数SEO知道在进行网站重新设计或CMS迁移时,需要将旧URL重定向到其较新的URL。 但是我看到太多的人检查了最初的301重定向并停止了研究。 不要犯错误。
301可能导致200标头响应代码,这很棒。 但是它也可能导致404,这不是很好。 或者它可以导致另一个301或另外五个301。 或者可能导致500(应用程序错误)。 仅仅因为URL 301重定向并不意味着它可以在重定向后正确解析。 这就是“ Screaming Frog”中“重定向链”报告的亮点。
确保选中设置中“始终遵循重定向”复选框,然后对那些旧的URL(需要重定向的URL)进行爬网。
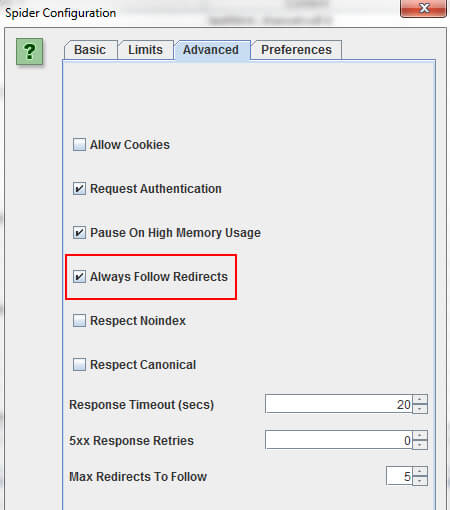
Screaming Frog将遵循重定向,然后提供从初始重定向到200、301、302、404、500等的完整路径。 要导出报告,必须在主菜单中单击“报告”,然后选择“重定向链”。
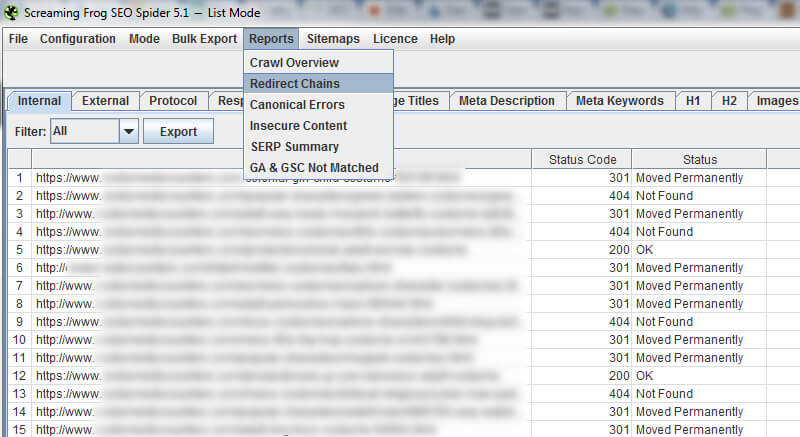
进入Excel后,您将看到重定向的原始URL,以及重定向到的URL的解析方式。 如果第二个URL重定向,则可以遵循重定向链。 同样,这是至关重要的。 如果您的301导致404,那么您可能会失去排名和访问量,而这些排名和访问量过去一直排名靠前。 至少可以这样说,这不好。

不安全的内容
由于Google施加了压力,因此许多网站都在使用HTTPS。 移至HTTPS时,有几项要检查以确保正确处理了迁移。 其中一项是确保您不会遇到内容不匹配的问题。 那就是当您通过安全URL传递不安全的元素时。
如果这样做,您将看到如下错误:
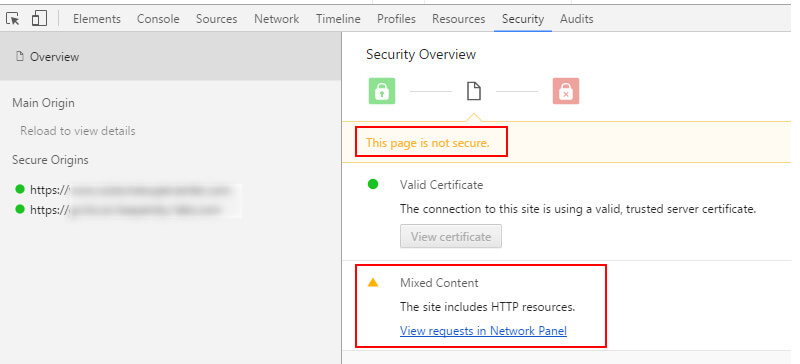
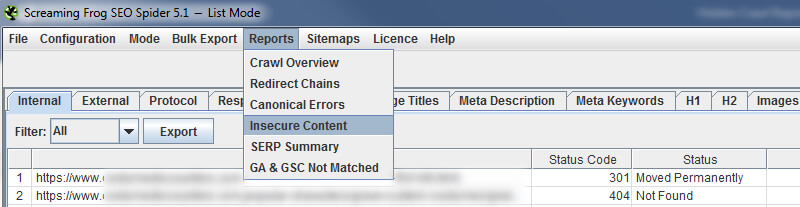
许多人不知道这一点,但是Screaming Frog内置了一份报告,显示不安全的内容。 再次转到主菜单中的“报告”下拉菜单,然后选择“不安全的内容”。 该报告将列出不安全内容的来源以及将其传递到哪些HTTPS URL。
迁移到HTTPS后运行报表后,即可将其导出并将数据发送给开发人员。
规范错误
规范的URL标记是确保搜索引擎了解您首选的URL(应建立索引的正确页面)的有力方法。这可以帮助减少重复的内容,并且可以将多个URL的索引属性合并到规范中一。
但是规范的URL标记也是用一行代码销毁SEO的好方法。 多年来,我已经看到许多规范标签的拙劣实现。 在最坏的情况下,它可能会导致大量的SEO问题-例如,将整个网站规范化为主页,或将rel规范化指向404页面,重定向到404等。
破坏相关规范有很多方法,但是SEO的问题在于它位于表面之下。 该标签用肉眼不可见,这使其非常非常危险。 因此,Screaming Frog提供了“规范错误”报告,可以帮助您快速发现这些问题。 只需再次转到“报告”菜单,然后选择“规范错误”即可。
导出报告后,您将看到Screaming Frog在爬网过程中拾取的每个规范错误。 您可能会对发现的结果感到震惊。 好消息是,您可以将报告发送给您的开发团队,以便他们找出发生这些错误的原因并进行必要的更改以解决核心问题。
使用DeepCrawl更深入
分页:第一页
分页在大型站点中很常见,尤其是包含许多产品类别的电子商务站点。
但是对于许多SEO来说,分页也是一个令人困惑的主题,从技术SEO的角度来看,这通常会导致设置不正确。 从noindexing组件页面,到将noindex和rel next / prev标签混合到其他有问题的组合,您通常可以向Google发送关于分页的非常奇怪的信号。
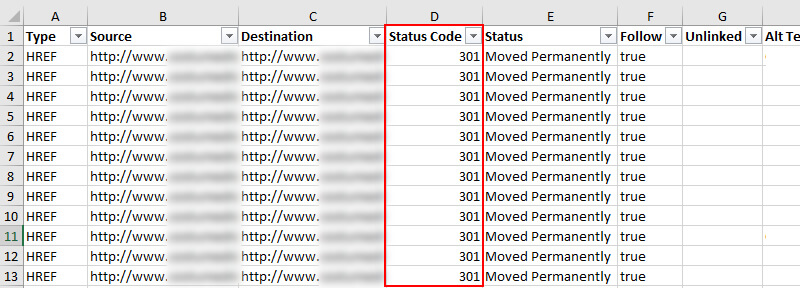
DeepCrawl 1.9(当前版本)包含一些非常有价值的报告,可以帮助您查找这些问题。 例如,当您在爬行大型复杂站点时,分页有时可能位于站点深处(超出明显区域)。 “第一页”报告将向您显示分页中的第一页(包含rel =“ next”标记的URL)。 这可以帮助您跟踪大型网站上许多分页实例的起点。
单击“内容”选项卡,然后滚动到内容报告的底部,即可在DeepCrawl中找到一组分页报告。 这是“首页”报告的屏幕截图。
通过“首页”报告找到分页之后,您可以更深入地了解分页是否已正确设置。 组件页面是否链接在一起? rel next / prev是否正确使用? rel规范如何? 组件页面是否没有索引? 他们被规范化到首页了吗?

您可以找到所有这些问题以及更多的答案。 但同样,您需要首先找到所有分页实例。 这就是该报告的帮助。
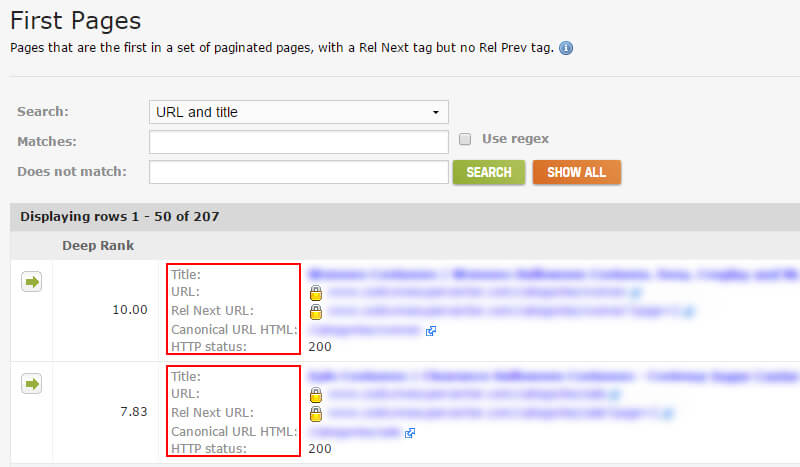
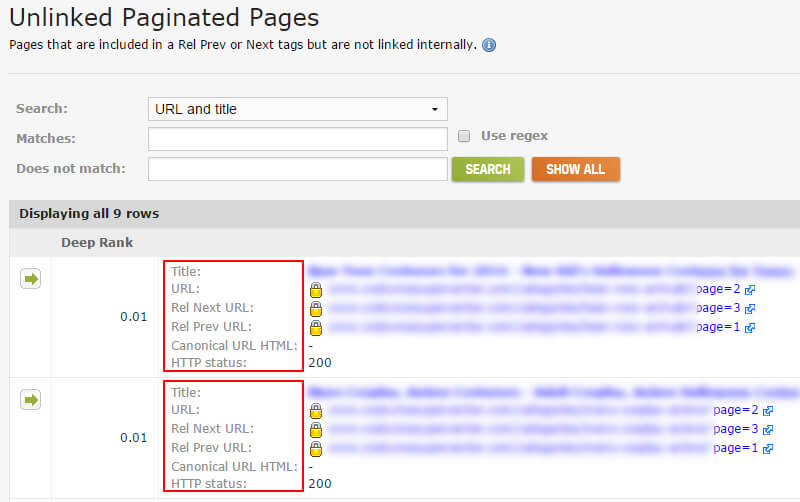
分页:未链接的分页页面
下一个难题是跟踪包含在rel next / prev标签中但未在网站上链接在一起的组件页面。 查找这些页面可以帮助解决技术性SEO问题。 例如,包含rel next标签的URL应该链接到**中的下一个组件页面。 同时具有rel =“ next”和rel =“ prev”的页面应链接到上一页和下一页。 等等等等。
如果您在未将URL链接在一起的情况下找到rel next / prev标签,则可能表明存在更深的问题。 也许网站上有旧代码应被删除。 也许应该有到组件页面的链接,但是它们没有出现在代码或页面上。 也许没有“下一页”,但是仍然有一个rel =“ next”标记,它指向404。同样,直到深入研究,您才知道将要找到的内容。
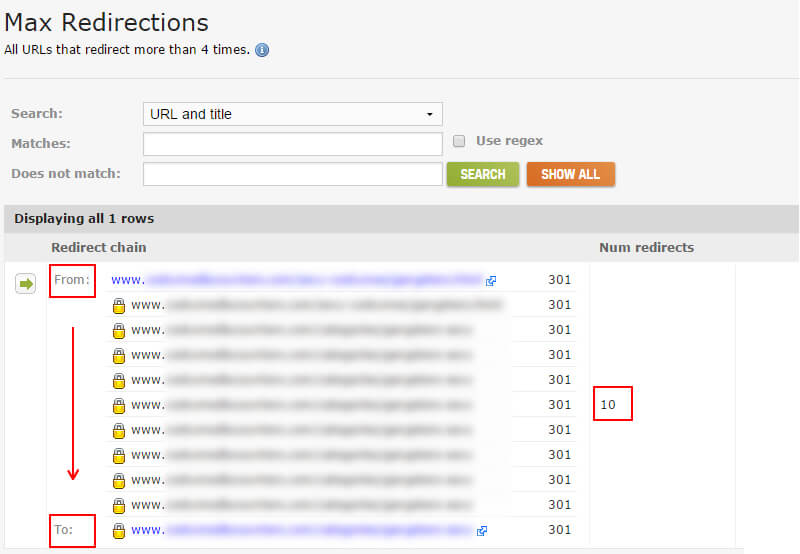
最大重定向
我之前提到过,有些将菊花链重定向到更多重定向。 并且当这种情况发生多次时,可能会导致SEO问题。 请记住,如果可能的话,您应该一次重定向到目标页面。 正如Google的John Mueller解释的那样,如果Google看到超过五个重定向,则它可能会停止跟踪,并且可能会在下一次爬网期间重试。
DeepCrawl提供了“最大重定向”报告,其中提供了所有重定向超过四次的URL。 这是轻松查看和分析这些URL的好方法。 当然,您可以跳转以快速修复这些重定向链。 您可以在DeepCrawl中找到“最大重定向”报告,方法是单击“验证”标签,然后滚动到标有“其他”的部分。
带有hreflang标签的页面(不包含)
Hreflang是将多个语言URL捆绑在一起的好方法。 然后,Google可以根据用户的语言在SERP中提供页面的正确版本。
但是根据我的经验,我在审核过程中看到了大量的hreflang错误。 例如,您必须在集群中其他页面引用的页面上包含返回标记。 因此,如果您的“ zh”页面引用了“ es”页面,则“ es”页面也必须引用“ zh”页面。 这是一个显示在Google Search Console中的“ no return tags”错误的示例。
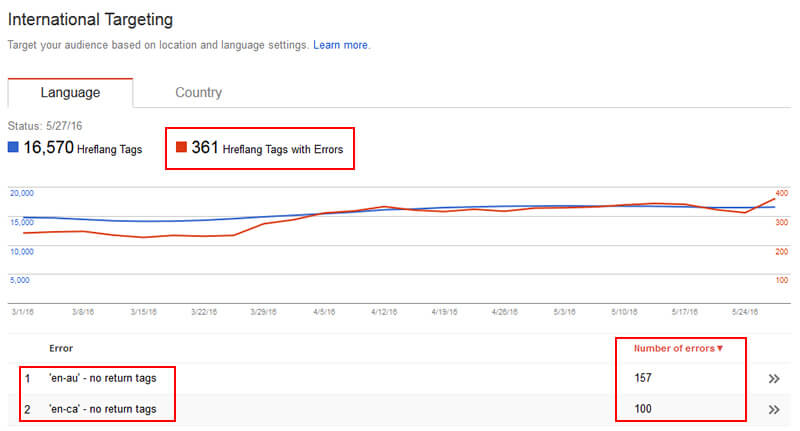
此外,还有其他方法可以破坏hreflang标记,例如提供不正确的语言和国家/地区代码,不正确地使用x-default等。 因此,您绝对想知道所有包含hreflang的页面,以便您可以更深入地了解这些标签是否设置正确。
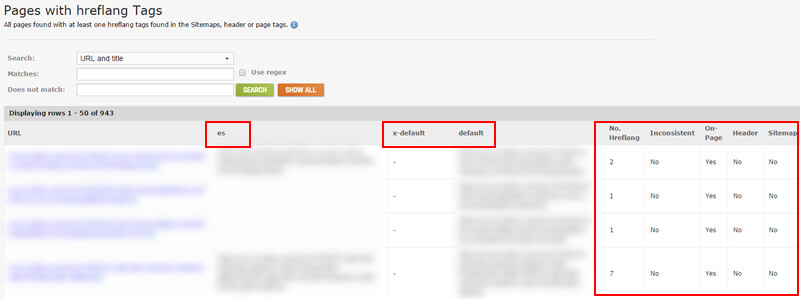
在DeepCrawl中,有一些报告可用于分析hreflang。 最基本但仍功能强大的是“带有hreflang标签的页面”报告。 它将列出所有包含hreflang标记的页面,提供在每个页面上找到的所有标记,并指示它们是通过XML网站地图以页面HTML形式提供,还是通过响应标头提供。 您可以在DeepCrawl中找到hreflang报告集,方法是单击“验证”标签,然后滚动到标有“其他”的部分。
请记住,对网页的标记更容易收拾,因为它们中的代码,但是当的hreflang通过响应头或在站点地图提供,你不会知道,通过简单地查看页面。 DeepCrawl的hreflang报告将为您显示此信息。
奖励:DeepCrawl 2.0即将发布
我之前提到过,我是DeepCrawl客户咨询委员会的成员。 好吧,我一直在测试Beta版的最新版本2.0版,并且即将发布。 作为2.0版的一部分,有一些新的和非常有价值的报告。 我将在下面介绍其中的两个。 请记住,您无法在当前版本(1.9)中访问这些报告,但将能够在2.0版本中使用,该版本应在接下来的几周内启动。
不允许的JS / CSS
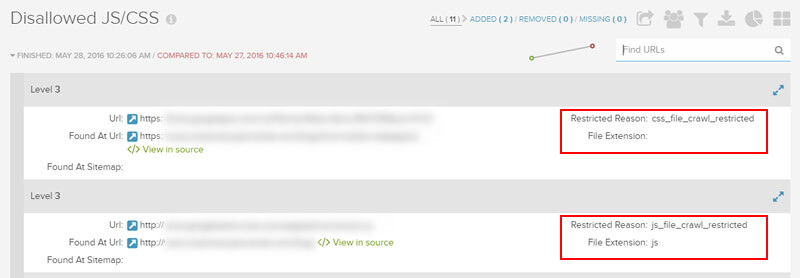
为了使Googlebot准确呈现网页,它需要检索必要的资源(如CSS和JavaScript)。 如果这些资源被robots.txt阻止,则Google将无法像典型浏览器那样准确地呈现页面。 Google记录在案,说明封锁资源可能“损害您的网页索引”。 至少可以这样说,这不好。
在Google Search Console中使用Google抓取方式并选择“抓取并呈现”是一种检查Googlebot如何呈现单个页面的好方法。 但是,如何检查50,000页,500,000页,1,000,000页或更多页呢? 好吧,DeepCrawl 2.0中有一个新报告,该报告显示了JavaScript和CSS等不允许的资源,这是一种快速查看站点上哪些资源被阻止的好方法。 然后,您可以快速纠正这些问题。
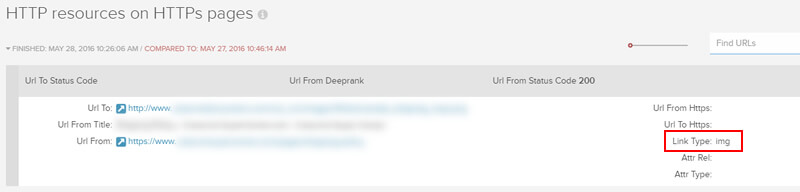
HTTPS上的HTTP资源
有许多站点急切地转向HTTPS。 但是,也有许多站点不正确地通过HTTPS提供HTTP内容(这将导致内容不匹配错误)。 DeepCrawl 2.0使您能够在大规模爬网中发现该问题。 确定要在HTTPS上传递的HTTP资源后,就可以与开发人员一起解决该问题。
后续步骤:确保您检查了这些容易错过的抓取报告
好的,现在您有九个其他报告需要分析,而不是您可能已经知道的报告(在Screaming Frog和DeepCrawl中)。 我在这篇文章中介绍的报告提供了大量重要数据,可以帮助您解决SEO技术问题。 这些问题可能会阻碍您在自然搜索中的表现。 因此,请爬开,然后检查那些报告! 您永远都不知道要找到什么。
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/9659.html