最新授予的Google专利揭示了搜索引擎如何看待实体

任何认识我的人都知道我是阅读Google专利的忠实拥护者,或者当我感到懒惰时,可以在他的博客SEO By The Sea中阅读Bill Slawski对它们的分析。
我也对涉及实体的实体特别感兴趣,因为它们(至少对我而言)是定义Google试图解决的问题的实体。 随着机器学习的发展,实体代表了搜索引擎如何看待世界。
在研究2016年12月22日授予的最新Google专利之前,让我们首先定义一个实体,以确保我们都在同一页面上。 根据该专利,定义如下:
[a] n实体是单个,唯一,定义明确和可区分的事物或概念。 例如,实体可以是人,地方,项目,想法,抽象概念,具体元素,其他合适的事物或其任意组合。
为简单起见,您可以随意将实体视为名词。
要理解的另一个重要定义是非结构化数据,它在Wikipedia中非常准确地定义为:
非结构化数据…是指没有预先定义的数据模型或未按照预先定义的方式组织的信息。
有了这些,我们将直接研究该专利。 本文的结构方式将以斜体的形式包括专利重要部分的确切说明,然后解释每个部分的含义。
抽象
提供了用于集体对帐的方法,系统和计算机可读介质。 在一些实施方式中,接收查询,其中该查询至少部分地与实体的类型相关联。 至少部分地基于查询来生成一个或多个搜索结果。 检索与一个或多个搜索结果中的至少一个搜索结果相关联的先前生成的数据,该数据包括在至少一个搜索结果中与实体类型相对应的一个或多个实体引用。 对一个或多个实体引用进行排名,并且至少部分地基于排名从一个或多个实体引用中选择实体结果。 至少部分地基于实体结果来提供对查询的答案。
这是摘要之一,几乎无法描述专利所含内容的全部范围。 就摘要而言,我们将要阅读的是对实体进行排名,而排名决定了查询的答案。
这足以吸引我加入该专利,而且确实是准确的-但正如您很快就会看到的那样,其中的描述远不止一个简单的“我们对名词进行排名”。
概要
以下摘录包含在专利的摘要部分中。
第二节
[A]系统通过依赖基于与搜索结果相关的非结构化数据中标识的实体引用来提供自然语言搜索查询的答案。 ……系统检索与至少某些搜索结果的各个网页相关联的附加预处理信息……例如,附加信息包括出现在网页中的人员的姓名。 在一个示例中,为了回答“谁”问题,系统会编译出现在前十个搜索结果中的名称,如附加信息中所标识。 系统将最常出现的名称标识为答案……
在上面的摘录中,我们开始看到系统背后的方法。 Google在这里讨论的想法是,要确定“谁”问题的答案,他们将使用出现在前10个搜索结果中的最通用名称。
第4节
查询是一种自然语言查询……对一个或多个实体引用进行排名包括基于至少一个排名信号进行排名。 在一些实施方式中,一个或多个排序信号包括每个相应实体参考的出现频率。 在一些实施方式中,一个或多个排序信号包括每个相应实体参考的话题性得分。 在一些实施方式中,先前生成的数据对应于非结构化数据。
为了进一步了解专利中如何概述该方法的信息,我们看到了在文档中以及大概在多个文档中使用该术语的频率。 另外,我们看到话题性是一个相关因素,并且这是一种应用于非结构化数据的方法。
第5节
可以以自动且连续更新的方式为查询提供[Q]种。 在一些实施方式中,问题回答可以利用搜索结果排名技术。 在一些实现中,可以基于诸如因特网的网络的非结构化内容来自动识别问题答案。
在本节中,我们看到它加强了可以根据搜索结果或排名技术确定问题的答案的方法,但是似乎我们也看到该专利正在扩展,包括基于其他技术及其能力的自动确定问题的答案。以确定非结构化数据中的答案。
专利US 2016/0371385 A1的真肉
第14至96节详细介绍了此专利中包含的图像,流程图和真实的肉。 一些图像将包含在下面,一些图像将被简单地注明,具体取决于哪个可以更好地传达信息。
第19节
系统可以检索与前十个搜索结果相关联的实体引用。 …排名和/或选择基于质量得分,新鲜度得分,相关性得分,任何其他合适的信息或其任意组合。
在这里,我们看到Google澄清了不同类型的实体和答案可能基于不同的信息集。 例如,如果您正在查找天气,则可以将新鲜度选择为更强的信号,而如果您正在查找定义,健康信息等,则质量可能会更强。
第20节
我承认,我必须阅读本节几次才能完全掌握他们在说什么。 本部分涉及专利图1,如下所示:
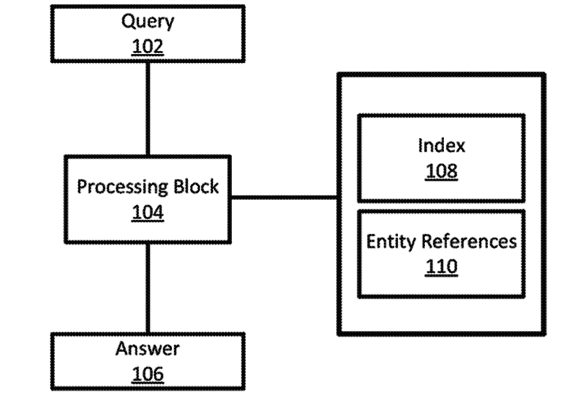
图1:根据本公开的一些实施方式的用于问题回答的系统的高级框图。
他们写:
从与特定网页相关联的实体参考110中检索到的信息是该网页中出现的人员的列表。 例如,特定网页可以包括多个人的名字,并且实体引用110可以包括网页内包括的名字的列表。 实体参考110还可以包括其他信息。 在一些实施方式中,实体参考110包括不同类型的实体参考,例如,人,地点和日期。 在一些实现中,用于多种实体类型的实体引用被保持为实体引用的单个注释列表,分离列表,以任何其他合适的信息格式或其任何组合。 将理解的是,在一些实施方式中,实体引用110和索引108可以存储在单个索引,多个索引,任何其他合适的结构或其任何组合中。
他们在这里指的是背后的想法,在专利的其他地方也有重复。 我在阅读该专利时遇到的主要问题之一是它将需要巨大的处理能力。 如果对于任何实体搜索,引擎都需要对自己的索引进行查询,则需要处理前10个结果,然后确定最常用的术语是为了确定最可能的问题答案,因此搜索结果的处理方式如下:这将需要很多倍的资源。
在第20节中,他们讨论了围绕此方法的方法,该方法是预先填充与索引本身分开的参考列表(图中的110)。
因此,当输入“ who is dave davies”这样的查询时,该数据是从索引中提取的(以确定可能具有答案的页面),但是还存在第二个参考点(110),其中将包含实体数据(例如每个文档中提到了“戴维·戴维斯”的次数),从而使Google无需即时解决。
第21节
使用[一个]或多个排名指标来对实体引用进行排名,包括出现频率和主题得分。 发生频率与实体引用在特定文档,文档**或其他内容中发生的次数有关。 时事性得分包括实体参考与其出现的内容之间的关系。
除了重复使用术语作为度量的次数之外,我们还在本节中看到话题性的增强。 虽然这可能与网站与主题的相关性有关,并应给出参考的权重,但我倾向于认为,它与帮助理解所参考的实体更多有关。
例如,如果在与SEO相关的页面上看到“ dave davies”实体,则可能是我。 另一方面,如果“ dave davies”出现在与音乐相关的页面上,则很可能是“那个Kinks家伙”(我喜欢提到他)。
在与音乐有关的页面上看到更多的“戴维·戴维”,将有助于他们选择展示:
第25条
系统会根据一个或多个质量得分对搜索结果进行排序。 在一些实施方式中,质量分数包括与搜索查询的相关性,与搜索结果相关联的质量分数,与上一次生成或更新内容的数据的时间相关联的新鲜度分数,与先前对特定搜索结果的选择相关联的分数。从搜索结果,任何其他合适的质量得分或其任意组合中收集。 在示例中,与搜索结果相关联的质量得分可以包括去往和来自对应网页的链接的数量。
在第25节中,我们将更多地说明质量得分作为指标。 当然,必须包括此部分,不仅因为其将传入链接作为质量指标进行引用,而且还包括将出站链接作为可能的信号。
第28节
该系统通过将结构化或非结构化文本与已知实体引用的列表(例如名称列表)进行比较来生成出现在网页中的实体引用的**。 在一些实现中,基于出现的频率或其他聚类技术来识别先前未知的实体引用。 在一些实现中,实体引用是人实体引用,例如,出现在网页文本中的人的名字。 在一个示例中,系统维护出现在特定网页中的所有人的所有姓名的列表,并且当该网页出现在搜索结果框206的顶部结果中时检索该列表。
在第28节中,我们了解到并不是所有实体都是已知的,因此需要开发方法来理解新实体。 如果首先在互联网上提到一个人,开发了一座新建筑物,等等,就会发生这种情况。 然后,Google将利用他们对如何引用其他实体的理解(例如,页面上的位置),并开始将新实体添加到实体引用列表中(请参见上面的图1中的“ 110”)。
第36条
在一些实施方式中,系统处理网页和其他内容以识别实体引用。 在一些实施方式中,系统离线执行该处理,使得在搜索时将其检索。 在一些实施方式中,系统在搜索时实时处理信息。
在第36节中,我们看到正在讨论的系统可以通过脱机处理获得更快的结果,就像我们在第20节中看到的那样。我们还看到了对实时运行的系统的引用。 显然,有些查询类型将需要此信息(例如天气),并且可以假设Google拥有此类信息的可信来源列表,从而使他们仍然能够以最少的资源快速处理信息。
第37节
[ist]个条目包括实体参考,与实体参考相关联的唯一标识符,实体参考的出现频率,实体参考在页面上的位置,与内容相关的元数据(例如新鲜度和顺序),任何其他合适的数据,或其任何组合。 在一些实施方式中,先前生成的数据可以包括实体参考的类型,例如,人,位置,日期,任何其他合适的类型或其任意组合。 在一些实施方式中,先前生成的数据包括将实体识别为特定类型的信息,例如人实体参考,地点实体参考或时间实体参考。 在一些实施方式中,可以为网站或其他内容生成多组数据,其中每组与一个或多个类型相关联。 在示例中,网站可以与其中发生的个人实体参考列表和其中发生的位置实体参考列表相关联。
对于那些对如何隔离不同实体感到好奇的人,我们在这里得到答案,他们在其中讨论实体的“唯一标识符”。 也就是说,本文的作者并没有想到《 The Kinks》和Dave Davies的Dave Davies,而是“ Dave Davies”的两个版本,而是将我们视为具有相同属性的标识符。

在您或我想起某人名字的地方,Google不会; 他们会以独特的(可能是字母数字)序列来思考它们。 我将在下面进一步说明,但以最简单的形式,它可能类似于:
唯一ID(00000001A)–>具有名称(Dave Davies)->具有工作(音乐家)
和
唯一ID(00000001B)–>具有名称(Dave Davies)->具有职位(SEO)
除此之外,本节主要增强了已知的SEO和相关性增强因素,例如实体使用的频率,内容在页面上的位置,链接等。
第38条
内容中出现的[其他]名称或实体引用可以用于消除引用的歧义。 在示例中,与[玛莎·华盛顿]相同的文本中出现的[乔治·华盛顿]名称可能被标识为与美国总统名单中的唯一实体参考相关,而[乔治·华盛顿]的名称与[大学]和[华盛顿特区]被确定与[乔治华盛顿大学]有关。
在本节中,我们进一步了解如何通过上下文理解实体。 当存在两个或更多个具有相似名称属性的实体时,该专利概述了使用页面中的其他数据来帮助确定所引用的是哪个特定实体。
以我的示例为例,对出现在“ The Kinks”页面上的“ Dave Davies”的引用将与上面具有唯一ID 00000001A而不是00000001B的Dave Davies相关联。
第41条
在另一个示例中,系统通过根据文档的长度或任何其他合适的度量对出现次数进行归一化来确定频率。
老实说,在这篇文章中我将第41节的一部分包括在内的唯一原因是,很可能是我最后一次能够在2000年代初没有上下文的情况下将关键字密度作为指标来使用。 ”
有趣的是,这正是他们在这里指的,在这种情况下,这确实是有道理的。 如果使用前10名结果中的实体引用频率作为对问题答案的指示,则应考虑到预期10,000字的页面对该数字的影响将不同于页面的影响。 700个单词。
尽管如此,您可能永远不会再阅读或听到唯一ID 00000001B对关键字密度的引用。
第42节
系统使用话题性得分作为排名信号。 在一些实现中,话题性得分包括新鲜度,文档的年龄,去往和/或来自文档的链接的数量,先前搜索结果中该文档的选择数量,文档与查询之间的关系强度。 ,任何其他合适的分数或其任意组合。 在一些实施方式中,话题性得分取决于实体参考与实体参考在其中出现的内容之间的关系。 例如,实体参考[乔治华盛顿(George Washington)]在历史网页上的话题性得分可能比在当前新闻网页上的话题得分更高。 在另一个示例中,政治网站上的实体引用[Barack Obama]的话题性评分可能比法学院网站上的话题评分更高。
在本部分中,我们将看到Google阐明了主题性的含义以及其对结果的影响。 这与选择特定实体作为答案(例如,选择要引用的Dave Davies)没有多大关系,而与用于制作答案的数据有关。
例如,他出生时是八个孩子中的最后一个孩子,因此在局部意义上不够相关,因此无法包含在“谁是戴维·戴维斯”的答案中,如上所示,而诸如他的出生日期和乐队等信息就可以了。 所有这些信息都是准确的,但是由于时事性信号(例如文档之间的频率),因此选择了更为“重要”的信息。
第47节
如果我们想真正了解Google如何回答问题和组织数据的逻辑,那么第47节可以说是最重要的数字。 因此,在深入探讨书面内容之前,我们先来看一下插图。 重要的是要注意,红色文字不是初始专利的一部分,而是由我添加以提供上下文的。
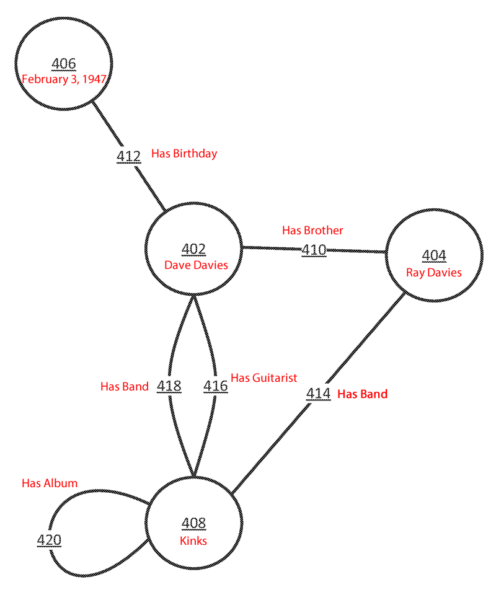
每个节点包含一个或多个数据,并且边缘表示边缘连接的节点中包含的数据之间的关系。 在一些实现中,图包括通过边缘连接的一对或多对节点。 边缘以及因此的图形可以是有向的,即单向的,无向的,即是双向的,或两者都有,即在同一图形中一个或多个边缘可以是无向的,一个或多个边缘可以是有向的。
引用的节点是圆形元素并包含数据; 线是边缘,包含关系。 例如,戴夫·戴维斯(402)拥有兄弟雷·戴维斯(404),并且都拥有乐队The Kinks(408)。
此图非常简化,以方便理解。 实际上,这些节点中的每个节点都表示唯一ID,并且这些ID将具有元素“具有名称”-但出于此处的目的,上面的插图很好地工作了。
第52条
域是指相关实体类型的**。 例如,域[电影]可以包括例如实体类型[演员],[导演],[电影位置],[电影],任何其他合适的实体类型或其任意组合。 在一些实现中,实体与一个以上域中的类型相关联。 例如,实体节点[Benjamin Franklin]可以与域[Government]中的实体类型节点[Politician]以及域[Business]中的实体类型节点[Inventor]连接。
在本节中,我们将看到进一步的信息分组。 可以合理地假设,大多数或所有域也将是其他应用程序中的节点。 例如,“基努·里维斯”(Keanu Reeves)将是通过“作用”边缘与另一个节点“电影”链接的节点。 这两个节点都将包含在“电影”域中。
第56条
知识图可以包括用于区分和/或消除术语和/或实体的信息。 如本文所使用的,区分是指多个名称与单个实体相关联的多对一情况。 如本文所使用的,歧义消除是指相同名称与多个实体相关联的一对多情况。 在一些实施方式中,可以为节点分配唯一的标识参考。 在一些实施方式中,唯一标识参考可以是字母数字字符串,名称,数字,二进制代码,任何其他合适的标识符或其任意组合。 唯一标识参考可以允许系统将唯一参考分配给具有相同或相似文本标识符的节点。 在一些实施方式中,唯一标识符和其他技术被用在区分,消歧或两者中。
在第56节中,我们澄清了区分(解决一个实体有多个名称的情况,例如:电影,电影,轻弹)和歧义消除(解决了多个实体共享一个名称的情况,例如: Dave Davies)。
我们在唯一标识符及其使用部分中再次讲。 简而言之,您不是您,我们沟通的方式本身也没有实体。 每个实体都是唯一的ID,并且该唯一的ID被分配给包含更常见引用(例如名称和特征)的节点。
第58条
[T]这里可能是与城市[Philadelphia]相关的实体节点,与电影[Philadelphia]相关的实体节点,以及与奶油奶酪品牌[Philadelphia]相关的实体节点。 这些节点中的每个节点都可以具有唯一的标识参考,例如以数字形式存储,以在知识图中进行歧义消除。 在一些实施方式中,知识图中的歧义由多个节点之间的连接和关系提供。 例如,可以将城市[New York]与州[New York]进行歧义,因为该城市与实体类型[City]连接并且该州与实体类型[State]连接。 将理解的是,更复杂的关系也可以定义和消除歧义。 例如,节点可以由关联的类型,由特定属性连接到该节点的其他实体,其名称,任何其他合适的信息或它们的任何组合来定义。 这些连接可能有助于消除歧义,例如,连接到节点[美国]的节点[Georgia]可以理解为代表美国州,而连接到节点[Asia]和[Eastern]的节点[Georgia]欧洲]可以理解为代表东欧国家。
尽管第58节的重点是讨论如何通过其节点和连接来识别特定实体,但真正重要的是这是它们用来确定哪个答案更可能正确的方法。 这将基于本节中讨论的节点和先前讨论的域的组合。 如果我问Google问题:
“谁在费城?”
Google知道,根据问题类型(我在寻找人),最有可能提及的是电影“费城”。 可以用曾经去过这座城市的所有知名人士的名单来回答,但是这不太可能是我想要的信息。 因此,Google提供了基于电影的答案。 如果我将问题更改为:
“费城有多少人?”
Google给出的答案是155.3万。 它本可以用电影中的总数来回答,但它已根据可用实体和所查找数据的框架选择了认为最有可能被查找的答案。
第61条
节点和边定义实体类型节点及其属性之间的关系,从而定义架构。
在这里,我们看到Google通过创建其自己先前未定义的边缘和节点的架构,将非结构化数据实质上转变为结构。 例如,这将使Google能够为Person生成自己的架构,并不断调整,添加和删除与之关联的架构。
第68条
对于不同的相应域,不同的相应实体类型或根据任何其他合适的划界特征,可以维护[S]单独的知识图。
在本部分中,我们将看到Google为不同类型的数据创建不同类型的知识图。 即,根据所请求的信息类型,成帧答案有所不同。 我们将在下面解释为什么这很重要。
所以呢?
现在我们已经到了关键信息末尾,您可能会问,“那又如何?” 好问题。
虽然了解Google如何组织数据本身是一件好事,但我们可以从中删除一些具体可行的项目,这些项目可以显着提高我们的排名和相关性。 最好的部分是,它们并不难,实际上并不需要付出太多努力-只是了解您要查找的内容。
- 包括使您有意义的数据。 好的,现在我脱下“明显的船长”帽子,并指出,如果我们仅查看站点,就会得出答案,以及它在实体上拥有哪些数据,我们将对Google发现的相关内容有更深入的了解。该特定主题。 Google希望给出答案,但他们也希望用户可以根据需要访问更完整的数据。 因此,他们将更有可能对不仅拥有所需答案的站点进行排名,而且还可能会寻找支持信息的搜索者。
- 创建结构化的非结构化数据。 虽然使用标记为引擎构造数据显然是理想的选择,但对内容进行框架设置也很重要,这样就可以在没有信息的情况下连接信息。 Google正在寻找内容来确定自己的联系,因此使用“ Dave Davies是The Kinks的吉他手”之类的陈述将有助于Google专门了解您所指的Dave Davies,他的角色以及该角色是谁。对于。 诸如“ The Kinks的Dave Davies”之类的陈述可能会被选为正确的实体; 但是,数据将不会被视为完整。 对于Google来说很好,因为他们可以在许多其他地方获取此信息。 但是,如果我们想排名靠前,我们应该努力做到周密。
- 以及更多的结构。 之前已经有人说过,并且这项专利进一步加强了我们需要研究知识传递的方式并相应地构造我们自己的数据。 如果您对上面的“谁是戴维·戴维斯”这个问题给出了答案,则会看到答案是以段落格式给出的。 如果我们考虑专利,我们将认为Google就是通过这种方式将实体之间的点连接起来的。 因此,如果我们在Dave Davies上有一个页面,我们希望以段落格式而不是列表的形式来构造信息。 这与“我怎么...”类型的查询不同,后者通常诉诸于其答案格式的列表。 这是第68节中讨论的内容,它不仅会影响我们对问题的解答能力,还会影响Google如何解释我们的网站以及内容结构的有效性。
结论
在我看来,实体是Google理解算法中最重要的方面之一,而这项专利又进一步加深了人们的理解。 了解实体就是了解Google如何看待所遇到的一切之间的联系。 这有助于确定如何构造内容(以及内容应包括什么)以使其不仅相关,而且最相关。
您还想要什么呢?
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/9739.html