分析爬网数据时,请不要低估高级过滤的功能

在帮助客户应对主要算法更新,排除SEO技术问题等问题的同时,我经常审核大型站点。 几乎总是需要进行彻底的站点爬网(通常在整个参与过程中进行多次爬网)。 而且,当您搜寻可能在网站上造成严重破坏的SEO gremlins时,将爬网数据切成薄片并切成小块以集中分析非常重要。
通过良好的数据过滤,您通常可以发现可能导致严重问题的页面类型,部分或子域。 一旦浮出水面,您就可以对这些领域进行大量分析,以更好地理解核心问题,然后解决需要解决的问题。
从爬虫角度讲,我已经在搜索引擎领域,DeepCrawl和Screaming Frog中介绍了我的两个收藏夹。 两者都是出色的工具,我通常使用DeepCrawl进行企业爬网,而使用Screaming Frog进行外科爬网,这更加集中。 (注意:我是DeepCrawl的客户咨询委员会的成员。)我认为,结合使用DeepCrawl和Screaming Frog是杀手kill,同时使用这两种工具时,我经常说1 +1 = 3。
下面,我将介绍在两个工具中同时使用过滤的几个示例,以便您能体会我所指的含义。 通过过滤爬网数据,您将可以隔离并显示站点的特定区域以进行进一步分析。 在您开始执行此操作后,您将永远不会回头。 让我们摇滚。
DeepCrawl中的过滤示例
可索引页面
让我们从一个基本但重要的过滤器开始。 内容质量问题在多个级别上都可能是非常成问题的,您肯定要确保可索引页面上不存在那些问题。 Google从质量角度评估网站时,会考虑整个网站。 这包括每个被索引的页面。 这是约翰·穆勒(John Mueller)的一段视频,对此进行了解释。
因此,当您在网站上发现问题时,最好通过可索引的URL过滤该列表,以便将分析重点放在可能损害网站质量的页面上。 我并不是说要忽略其他URL,因为它们没有被索引! 您也应该完全照顾它们。 请记住,用户正在与这些页面进行交互,并且您不希望用户感到不愉快。 隔离在挖掘内容和/或其他质量问题时可以建立索引的页面是很聪明的。

内容稀疏+网页类型的正则表达式=很棒
对于那些喜欢正则表达式的人,我有个好消息。 DeepCrawl支持使用正则表达式进行高级过滤。 因此,您可以选择一个过滤器,然后选择“匹配正则表达式”或“不匹配正则表达式”以执行某些外科手术过滤。 顺便说一句,拥有“不匹配正则表达式”过滤器来清除您要排除的URL和包含的URL真是太棒了。
例如,让我们开始简单,使用管道字符在过滤器中组合三个不同的目录。 竖线字符在正则表达式中表示“或”。

或者,如何排除特定目录,然后关注仅以两个或三个字符结尾的URL(这是我认为在特定审核期间从内容角度来看是有问题的URL的实际示例):

或者,如何将页面类型的正则表达式与字数混合以按页面类型或目录识别真正的薄页面呢? 这就是为什么过滤如此强大(且节省时间)的原因。

您得到图片。 您可以包括或排除所需的任何类型的URL或模式。 而且,您可以在过滤器上分层以磨练报告。 聚焦大型爬网真是太神奇了。
规范问题:响应头
去年,我写了一篇文章,介绍如何检查X-Robots-Tag对潜在的危险机器人指令进行故障排除(因为它们可以通过标头响应传递,并且肉眼看不见)。 在大型站点上,这可能会非常危险,因为当页面在表面看起来不错时,可能会错误地将其索引。
好了,您也可以通过标头响应设置rel规范。 这可能会导致一些奇怪的问题(如果您不知道如何设置rel规范,可能会使您发疯。)在某些情况下,您可能会为一个URL带有多个规范标签(一个通过标头响应)并在html中设置一个)。 发生这种情况时,Google可以忽略所有规范标签,如他们在博客文章中有关rel canonical的常见错误所解释的那样。
通过检查“没有有效规范标签的页面”报告,然后通过rel规范标题URL和rel规范html URL进行过滤,可以发现存在此问题的所有URL。 然后,您可以与您的开发团队进行深入探讨,以确定为什么在代码方面会发生这种情况。

在URL找到! 确定错误链接的来源

毫无疑问,您将在大规模爬网(例如404、500和其他)中遇到爬网错误。 仅仅知道URL返回错误常常是不够的。 您确实需要跟踪从整个网站链接这些URL的位置。
您想要大规模解决问题,而不仅仅是一次性解决。 为此,请从任何爬网错误报告(或非200报告)中按“找到” URL进行过滤。 然后,您可以使用正则表达式显示可能大量链接到返回爬网错误的页面的页面类型和/或目录。

仔细检查AMP URL:所有相关链接
使用加速的移动页面(AMP)? 要通过html中的rel = amphtml仔细检查您所引用的URL,可以检查“所有rel链接”报告并按amphtml进行过滤。 然后,您可以对“ URL to”应用另一个过滤器,以确保这些URL确实是您引用的amp URL。 同样,这只是过滤如何发现表面之下险恶问题的另一个快速示例。

下载过滤的CSV
我在上面提供了几个示例,说明了在DeepCrawl中分析爬网数据时可以使用高级筛选执行的操作。 但是,当您要导出该数据时呢? 由于您在过滤方面做得非常出色,因此您绝对不想在导出时丢失过滤后的数据。
因此,DeepCrawl具有“生成过滤的CSV”的强大功能。 通过使用此功能,您可以轻松导出仅过滤数据,而不是整个玉米卷。 然后,您可以在Excel中进一步分析或发送给您的团队和/或客户。 太棒了
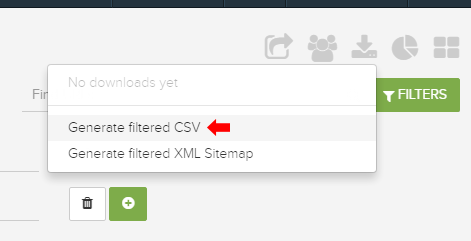
过滤青蛙尖叫
对于Screaming Frog,过滤器虽然不那么强大,但是您仍然可以在UI中过滤数据。 许多人不知道这一点,但是搜索框中支持正则表达式。 因此,您可以使用DeepCrawl(或其他地方)中使用的任何正则表达式来按Screaming Frog中的报告类型过滤URL。
例如,检查响应代码并想按目录快速检查那些URL? 然后使用管道字符包括特定的页面类型或目录(或模式)。 您将看到基于正则表达式的报告更改。
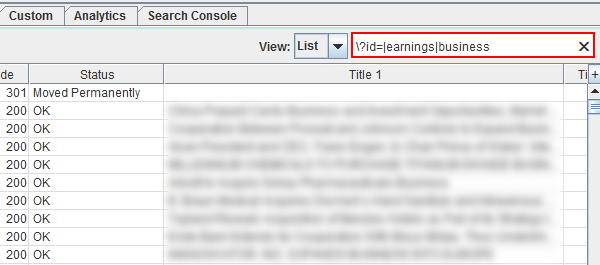
然后,您可以利用预先过滤的报告,然后分层进行自己的过滤。 例如,您可以检查标题较长的页面,然后使用正则表达式进行过滤以开始显示特定的页面类型或样式。
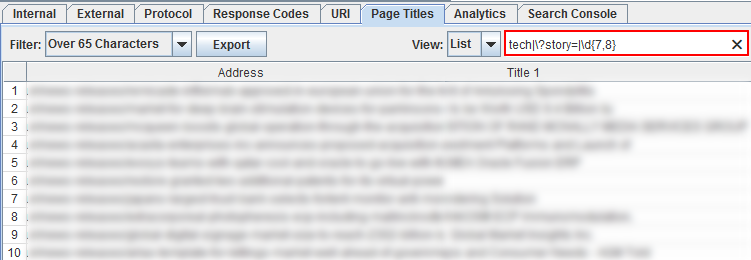
过滤器适用于所有列! 因此,您可以将正则表达式用于该特定报告中列出的任何列。 例如,下面我从所有包含规范URL标记的URL开始,然后使用“ noindex”显示包含meta robots标记的URL。
如果一个URL没有索引,则它不应包含规范的URL标记(两者相互抵触)。 Rel规范地告诉引擎哪个是用于索引的首选URL,而使用noindex的meta robots标签则告诉引擎不对URL进行索引。 这是没有意义的。 这只是您可以在Screaming Frog中进行过滤的简单示例。 注意:Screaming Frog有一个“ canonical errors”报告,但这是在UI中筛选出表面问题的快速方法。

从导出的角度来看,很遗憾,您不能仅导出过滤的数据。 但是您可以快速将过滤后的数据**并粘贴到Excel中。 谁知道,也许Screaming Frog的聪明人会建立“导出过滤数据”选项。

摘要:全部包含在过滤器中
我花了很多时间对网站进行爬网并分析爬网数据,但我对过滤的功能不够重视。 并且,当您添加正则表达式支持时,您实际上可以开始对数据进行切片和切块,以发现潜在的问题。 而且,您发现问题的速度越快,解决这些问题的速度就越快。 这对于具有数万,数十万甚至数百万个页面的大型站点尤其重要。 因此,继续…过滤掉。
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/9802.html