振作起来:通过日志文件分析Googlebot抓取峰值的好处和震惊[案例研究]

我最近开始帮助受5月17日算法更新影响的网站。 该网站已在质量上徘徊了很长时间,更新了一些质量,有时甚至下降。 因此,我开始通过爬网分析和对该站点的审核进行挖掘。
开始分析网站后,我注意到Google Search Console(GSC)的“抓取统计信息”报告中抓取的页面出现了一些奇怪的峰值。 例如,Google通常每天会抓取大约3,000页,但是前两个峰值猛增到将近20,000。 然后又有两个突破了11,000。
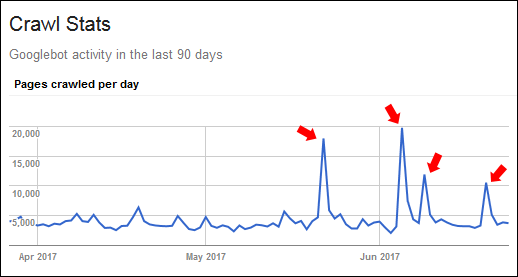
不用说,我有兴趣找出为什么会出现这些峰值。 网站上是否存在技术性SEO问题? 是否存在导致峰值的外部因素? 还是这是Googlebot异常? 我很快与客户联系了我所看到的。
尖峰爬行:有时是预期的,有时不是
我问我的客户,他们是否根据我的建议实施了任何大规模更改,这些更改可能会触发爬网高峰。 他们还没有。 记住,我刚刚开始帮助他们。
另外,我刚刚完成了两次大规模的网站爬网,没有看到任何奇怪的技术SEO问题,这些问题可能导致Googlebot爬网许多其他页面或资源:编码故障可能导致Google爬网许多重复的内容页面,错误的分页,多面导航等。 我在网站上没有发现任何这些问题(至少基于第一组爬网)。
现在,值得注意的是,当Google看到网站上的大规模更改时(例如,网站迁移,重新设计或网站上的许多URL发生更改),它可以增加抓取速度。 Google网站管理员趋势分析师John Mueller对此做了多次解释。
下图显示了外观。 这来自我正在帮助进行https迁移的网站(而不是我在本文中介绍的网站)。 请注意,迁移发生后,爬网便迅速增加。 这是完全正常的:
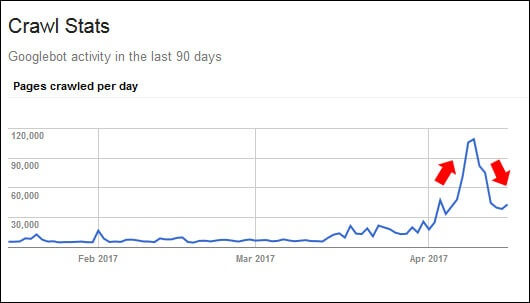
但这不是在这种情况下发生的事情。 该网站上尚未进行大规模更改。 审查情况后,我的决定很明确:
释放日志文件!
服务器日志的功能
日志文件包含网站活动的原始数据,包括来自用户和搜索引擎机器人的访问。 使用日志,您可以深入探究每次访问和事件,以查看正在爬网的页面和资源,返回的响应代码,引荐来源网址,IP地址等。 考虑到爬行的高峰,我很想看看。
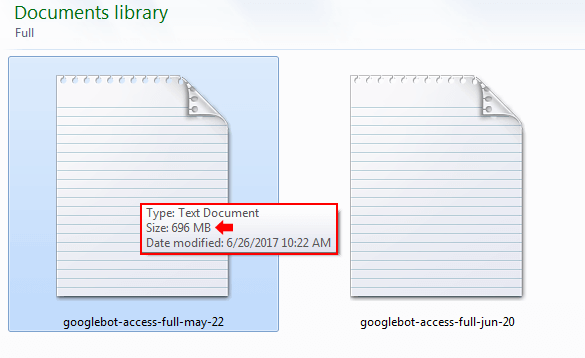
如果您从未处理过日志文件,则应该知道它们会变得很大。 例如,看到日志文件大小为数百兆字节(对于大容量站点甚至更大)的情况并不少见。 这是我正在使用的日志文件之一。 696MB。
记录,遇见青蛙
我的下一步是启动我最喜欢的日志分析应用程序Screaming Frog Log Analyzer(SFLA)。 你们大多数人都知道“尖叫青蛙蜘蛛”(Screaming Frog Spider),它对于爬网的站点非常有用,但有些人仍然不知道Dan Sharp和他的两栖SEO团队也创建了一个杀手级日志分析器。
我启动了SFLA并导入了日志。 我的客户向我发送了日志文件,范围从每次高峰前的几天到几天后的几天。 他们针对我在Google Search Console(GSC)的抓取统计信息报告中看到的每个峰值执行了此操作。 现在该进行挖掘了。我将日志文件拖到SFLA中,耐心地等待它们的导入。
休斯顿,我们有一个问题…
在分析第一组日志文件时,SFLA中的仪表板讲述了一个有趣的故事。 响应代码图表显示Googlebot遇到了404个峰值。 看来是问题所在。
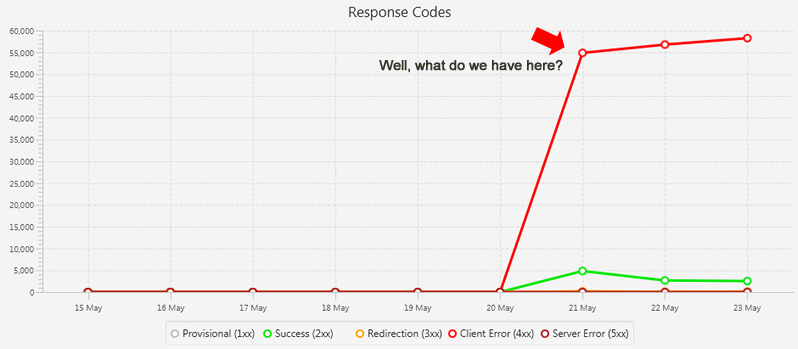
我注意到成千上万的事件导致了奇怪的URL,这些URL看起来像是包含视频的拙劣页面,而且我客户的网站不包含这些URL之一。 在此期间,大多数404都是由于网址异常。
但是,某些“ Googlebot”事件看起来有些不对劲。 接下来更多。
剧情变厚:欺骗
我总是警告人们,在他们深入日志文件之前,他们可能会看到一些令人不安的东西。 请记住,日志包含站点上的所有事件,包括所有机器人活动。 不幸的是,看到许多机器人爬网以获取情报……或出于更邪恶的原因,这并不罕见。
例如,您可能会看到抓取工具试图(通常是从竞争对手那里)了解有关您的网站的更多信息。 您还可以看到黑客尝试。 例如,来自随机IP地址的事件会影响您的WordPress登录页面。
首次发现时,您可能会像这样:

因此,这就是我从“ Googlebot”浮出水面的404峰值。 我很快注意到许多欺骗性的Googlebot事件(来自几个不同的IP地址)。 Screaming Frog Log Analyzer具有一个漂亮的“验证机器人”功能,我充分利用了这一功能。
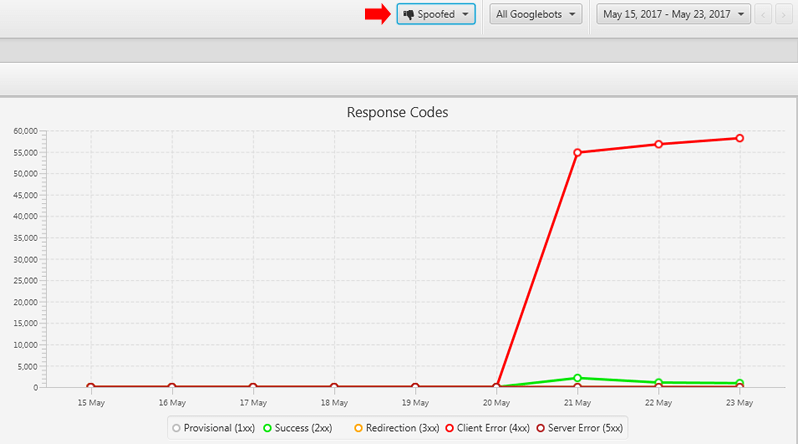
有趣的是,真正的Googlebot在此期间(通过GSC报告)激增,而被欺骗的Googlebot在此期间也对该网站产生了冲击。 但是我在日志文件中找不到任何经过验证的Googlebot峰值。
因此,我们收集并研究了一些不良行为IP,并发现它们并非来自Google。 我的客户现在正在处理这些IP。 这是一件很明智的事情,尤其是当您看到来自特定IP欺骗Googlebot的回访时。 我们也经历了第二个峰值。
这是举起引擎盖并发现发动机中一些疯狂问题的好例子(或者在发动机中添加了燃料)。 您可以震惊地发誓要关闭引擎盖,再也看不到它,或者可以长期解决这些问题。 彻底解决问题并不是解决问题的办法。
真正的Googlebot可以站起来吗?
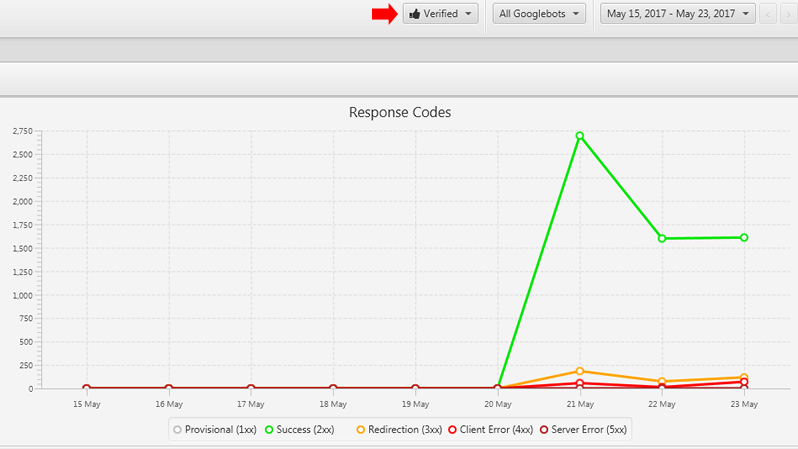
在分析了前两个峰值之后,我仍然没有看到任何经过验证的Googlebot问题。 (我指的是Google实际上是在爬网该站点,而不是欺骗Googlebot的不同爬网程序。)因此,GSC中的爬网统计数据确实增加了,但是服务器日志显示Googlebot正常活动。 欺骗的Googlebot似乎引起了问题。

在下面查看经过验证的Googlebot活动与欺骗活动:
检索数据恢复正常,然后再次上升
我们一直在GSC中检查抓取统计信息报告,以便经常监控情况(对于真正的Googlebot)。 爬网统计信息在一段时间内恢复正常,但第三和第四次出现峰值(如我在上面共享的第一幅屏幕截图所示)。 最新的峰值是抓取了超过11,000页。
查看日志后发现该站点上不存在许多URL(但以前的视频URL不存在)。 并已由Googlebot正确(已验证)访问。 我很高兴看到我们终于发现了一些真正的Googlebot问题(而不仅仅是欺骗性的Googlebot问题)。
这些URL看起来完全不完整,有时长度为数百个字符。 它看起来像是一个编码故障,不断向链接到的每个URL附加更多字符和目录。 我将信息发送给我的客户,然后他们将信息转发给了他们的主要开发人员。 他们最初不知道Google在哪里可以找到这些URL。 接下来,我将介绍它。
Googlebot和404s:SEO的细微差别
需要明确的是,如果页面实际上应该是404,则404并不是问题。Google的John Mueller对此进行了多次解释。 404在网络上是完全自然的,并且不会影响网站的质量。
这是约翰·穆勒(John Mueller)解释的视频:
这是Google的有关Googlebot如何在网站上遇到404的页面:
- 抓取错误:常见的网址错误
话虽如此,机器人和人们都可能访问导致404的链接,因此可能会影响可用性和性能。 正如穆勒在视频中解释的那样,“它会使抓取变得有些棘手。” 因此,您绝对应该仔细检查404,并确保它们确实返回404。但是,仅拥有404并不意味着您的网站将从排名的角度出发,不会受到下一个主要算法更新的打击等等。 要知道这一点很重要。
显而易见的是,所有404的页面都将从Google的索引中删除。 因此,该页面无法为曾经排名的查询排名。 它不见了,它所吸引的交通也消失了。 再次重申一下,只要确定404页面应该是404。
例如,想象一下像下面突然出现404(错误)这样的高容量页面。 当网址超出索引范围时,该网站将失去该页面的所有排名,包括点击量,广告展示次数等等。
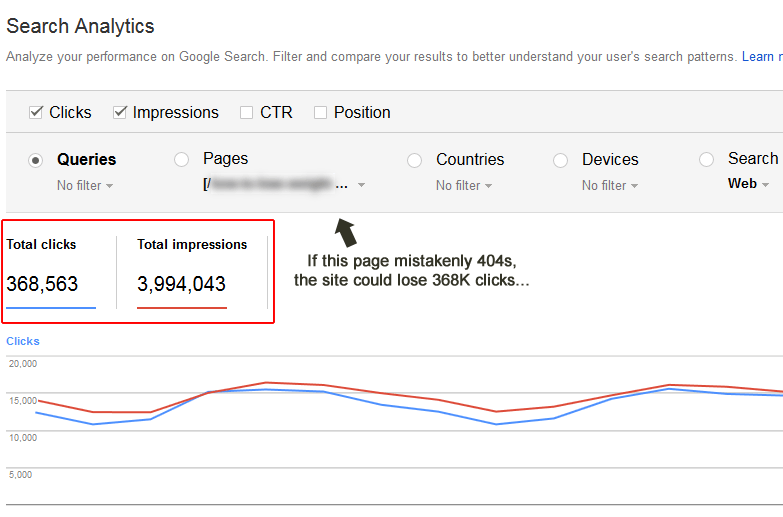
Google还在网站站长中央博客上写了一篇有关404的文章,这些文章是否会对您的网站造成伤害。 在Mueller的评论,支持文档和博客文章之间,您可以放心,仅404不会导致质量问题。 但是同样重要的是,要确保恶毒,欺骗性的Googlebot不会重击服务器以影响正常运行时间(以及长期的SEO)。
我问我的客户,基于我们看到的爬网峰值,该站点是否发现任何性能问题,很高兴听到他们根本没有发现任何问题。 该网站运行在功能非常强大的服务器上,当“ Googlebot”大量抓取时甚至没有引起注意。
Google如何找到这些长网址?
在分析了爬网到这些长URL的峰值之后,我可以看到损坏的URL与一些JavaScript文件之间的连接。 我相信Google会根据JavaScript代码找到网址(或形成网址)。
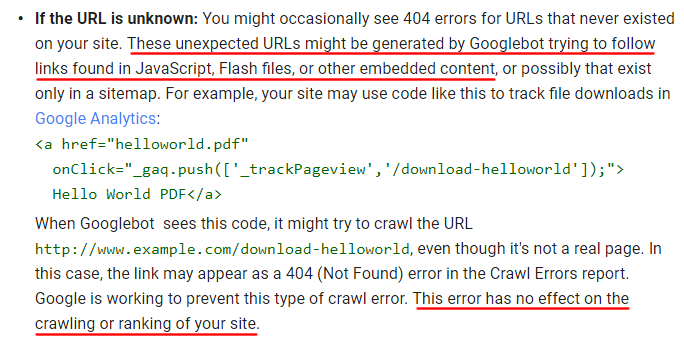
您会注意到Google在我上面列出的支持文档中提到了发生这种情况的可能性。 因此,如果您看到网站上没有出现Google抓取的URL,则Googlebot可能通过JavaScript或其他嵌入式内容找到了这些URL。 知道这一点也很重要。
我们学到了(没学到)
正如我之前所说,挖掘服务器日志既有益又令人不安。 一方面,您可以发现Googlebot遇到的问题,然后解决这些问题。 另一方面,您会看到更危险的事情,例如黑客入侵,欺骗的Googlebot爬网您的网站以获取情报,或进行其他尝试来破坏服务器。
通过此练习,我们学到了一些东西:
- 我们可以清楚地看到欺骗性的Googlebot蠕动了该网站,其中许多都击中了奇怪的404。 我的客户能够解决那些重击服务器的流氓IP。
- 我们看到了真正的Googlebot(已验证)正在爬网看起来是被篡改的URL(基于通过JavaScript找到的链接)。 利用这些数据,我的客户可以深入研究可能会产生那些冗长而拙劣的URL的技术问题。
- 我们没有找到Googlebot的所有尖峰都显示在GSC。 真奇怪,我不确定这是Google的报告问题还是其他原因。 但同样,我们确实从经过验证的Googlebot中发现了一些真正的峰值。
- 也许最重要的是,我的客户可以清楚地看到SEO的功能-例如,许多欺骗性的Googlebot爬网以获取情报,或者出于更邪恶的原因。 但是至少我的客户知道这正在发生(通过数据)。 现在,如果他们愿意,他们可以制定应对恶意机器人的计划。
摘要:日志文件可以揭示表面下的危险问题
当您对它进行分解时,网站所有者真的不了解有关谁或什么内容正在爬网其站点的全部信息,直到他们分析服务器日志为止。 Google Analytics(分析)不会提供此数据。 您必须深入查看日志,才能发现漫游器访问您的网站。
因此,如果您发现抓取峰值,并且想知道正在发生什么,请不要忘记您的日志! 它们可以成为宝贵的数据来源,有助于发现SEO的奥秘(以及可能需要解决的险恶问题)。 不要害怕挖掘答案。 只要记住,您可能需要做好准备。
本文中表达的观点是来宾作者的观点,不一定是Search Engine Land。 工作人员作者在此处列出。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.botadmin.cn/sylc/9854.html